VIPRS-grid#
VIPRS is challenging to implement and may have some errors.
Here, we will use a GRID VIPRS model to calculate the PRS.
Installation#
python_version=3.11 # Change Python version here if needed
conda create --name "viprs_env" -c anaconda -c conda-forge python=$python_version compilers pkg-config openblas -y
conda activate viprs_env
git clone https://github.com/shz9/viprs.git
Also, download the GitHub repository and place it in the working directory.
To use the author’s version, kindly refer to their documentation: VIPRS Documentation.
Possible Issues#
VIPRS has multiple versions, and if they update the version, the code may not work.
It requires a dedicated environment for execution.
Some of the models may not work due to various issues. I tried to find those issues, but did not get a concrete reason. For example:
VIPRSMix method does not work.
GS and BO hyperparameter search optimization does not work.
Environment#
Following is the content of the viprs_env_environment.yml. Copy the following content into viprs_env_environment.yml and execute:
conda env create -f viprs_env_environment.yml
conda activate viprs_env
And the following code will work.
name: viprs_env
channels:
- anaconda
- conda-forge
- bioconda
- defaults
dependencies:
- _libgcc_mutex=0.1=main
- _openmp_mutex=5.1=1_gnu
- _sysroot_linux-64_curr_repodata_hack=3=haa98f57_10
- binutils=2.38=h1680402_1
- binutils_impl_linux-64=2.38=h2a08ee3_1
- binutils_linux-64=2.38.0=hc2dff05_0
- blas=1.0=openblas
- bzip2=1.0.8=h5eee18b_6
- c-compiler=1.5.2=h0b41bf4_0
- ca-certificates=2024.7.2=h06a4308_0
- compilers=1.5.2=ha770c72_0
- cxx-compiler=1.5.2=hf52228f_0
- fortran-compiler=1.5.2=hdb1a99f_0
- gcc=11.2.0=h702ea55_10
- gcc_impl_linux-64=11.2.0=h1234567_1
- gcc_linux-64=11.2.0=h5c386dc_0
- gfortran=11.2.0=h8811e0c_10
- gfortran_impl_linux-64=11.2.0=h1234567_1
- gfortran_linux-64=11.2.0=hc2dff05_0
- gxx=11.2.0=h702ea55_10
- gxx_impl_linux-64=11.2.0=h1234567_1
- gxx_linux-64=11.2.0=hc2dff05_0
- kernel-headers_linux-64=3.10.0=h57e8cba_10
- ld_impl_linux-64=2.38=h1181459_1
- libffi=3.4.4=h6a678d5_1
- libgcc-devel_linux-64=11.2.0=h1234567_1
- libgcc-ng=11.2.0=h1234567_1
- libgfortran-ng=11.2.0=h00389a5_1
- libgfortran5=11.2.0=h1234567_1
- libgomp=11.2.0=h1234567_1
- libopenblas=0.3.21=h043d6bf_0
- libstdcxx-devel_linux-64=11.2.0=h1234567_1
- libstdcxx-ng=11.2.0=h1234567_1
- libuuid=1.41.5=h5eee18b_0
- ncurses=6.4=h6a678d5_0
- nomkl=3.0=0
- openblas=0.3.21=h06a4308_0
- openblas-devel=0.3.21=h06a4308_0
- openssl=3.0.14=h5eee18b_0
- pip=24.0=py311h06a4308_0
- pkg-config=0.29.2=h1bed415_8
- python=3.11.9=h955ad1f_0
- readline=8.2=h5eee18b_0
- setuptools=72.1.0=py311h06a4308_0
- sqlite=3.45.3=h5eee18b_0
- sysroot_linux-64=2.17=h57e8cba_10
- tk=8.6.14=h39e8969_0
- wheel=0.43.0=py311h06a4308_0
- xz=5.4.6=h5eee18b_1
- zlib=1.2.13=h5eee18b_1
- pip:
- annotated-types==0.7.0
- anyio==4.4.0
- argon2-cffi==23.1.0
- argon2-cffi-bindings==21.2.0
- arrow==1.3.0
- asciitree==0.3.3
- asttokens==2.4.1
- async-lru==2.0.4
- attrs==24.2.0
- babel==2.16.0
- beautifulsoup4==4.12.3
- bleach==6.1.0
- bokeh==3.5.1
- certifi==2024.7.4
- cffi==1.17.0
- charset-normalizer==3.3.2
- click==8.1.7
- cloudpickle==3.0.0
- comm==0.2.2
- contourpy==1.2.1
- cycler==0.12.1
- cython==3.0.11
- dask==2024.1.0
- debugpy==1.8.5
- decorator==5.1.1
- defusedxml==0.7.1
- deprecated==1.2.14
- executing==2.0.1
- fasteners==0.19
- fastjsonschema==2.20.0
- fonttools==4.53.1
- fqdn==1.5.1
- fsspec==2024.6.1
- h11==0.14.0
- httpcore==1.0.5
- httpx==0.27.0
- idna==3.7
- importlib-metadata==8.2.0
- iniconfig==2.0.0
- ipykernel==6.29.5
- ipython==8.26.0
- ipywidgets==8.1.3
- isoduration==20.11.0
- jedi==0.19.1
- jinja2==3.1.4
- joblib==1.4.2
- json5==0.9.25
- jsonpointer==3.0.0
- jsonschema==4.23.0
- jsonschema-specifications==2023.12.1
- jupyter==1.0.0
- jupyter-client==8.6.2
- jupyter-console==6.6.3
- jupyter-core==5.7.2
- jupyter-events==0.10.0
- jupyter-lsp==2.2.5
- jupyter-server==2.14.2
- jupyter-server-terminals==0.5.3
- jupyterlab==4.2.4
- jupyterlab-pygments==0.3.0
- jupyterlab-server==2.27.3
- jupyterlab-widgets==3.0.11
- kiwisolver==1.4.5
- locket==1.0.0
- magenpy==0.1.3
- markupsafe==2.1.5
- matplotlib==3.9.1.post1
- matplotlib-inline==0.1.7
- mistune==3.0.2
- multimethod==1.10
- mypy-extensions==1.0.0
- nbclient==0.10.0
- nbconvert==7.16.4
- nbformat==5.10.4
- nest-asyncio==1.6.0
- notebook==7.2.1
- notebook-shim==0.2.4
- numcodecs==0.13.0
- numpy==1.26.4
- overrides==7.7.0
- packaging==24.1
- pandas==1.5.2
- pandas-plink==2.2.4
- pandas-stubs==2.2.2.240807
- pandera==0.20.3
- pandocfilters==1.5.1
- parso==0.8.4
- partd==1.4.2
- patsy==0.5.6
- pexpect==4.9.0
- pillow==10.4.0
- platformdirs==4.2.2
- pluggy==1.5.0
- prometheus-client==0.20.0
- prompt-toolkit==3.0.47
- psutil==6.0.0
- ptyprocess==0.7.0
- pure-eval==0.2.3
- pycparser==2.22
- pydantic==2.8.2
- pydantic-core==2.20.1
- pygments==2.18.0
- pyparsing==3.1.2
- pytest==8.3.2
- python-dateutil==2.9.0.post0
- python-json-logger==2.0.7
- pytz==2024.1
- pyyaml==6.0.2
- pyzmq==26.1.0
- qtconsole==5.5.2
- qtpy==2.4.1
- rechunker==0.5.2
- referencing==0.35.1
- requests==2.32.3
- rfc3339-validator==0.1.4
- rfc3986-validator==0.1.1
- rpds-py==0.20.0
- scikit-learn==1.5.1
- scipy==1.14.0
- seaborn==0.13.2
- send2trash==1.8.3
- six==1.16.0
- sniffio==1.3.1
- soupsieve==2.5
- stack-data==0.6.3
- statsmodels==0.14.2
- tabulate==0.9.0
- terminado==0.18.1
- threadpoolctl==3.5.0
- tinycss2==1.3.0
- toolz==0.12.1
- tornado==6.4.1
- tqdm==4.66.5
- traitlets==5.14.3
- typeguard==4.3.0
- types-python-dateutil==2.9.0.20240316
- types-pytz==2024.1.0.20240417
- typing-extensions==4.12.2
- typing-inspect==0.9.0
- tzdata==2024.1
- uri-template==1.3.0
- urllib3==2.2.2
- viprs==0.1.2
- wcwidth==0.2.13
- webcolors==24.8.0
- webencodings==0.5.1
- websocket-client==1.8.0
- widgetsnbextension==4.0.11
- wrapt==1.16.0
- xarray==2024.7.0
- xyzservices==2024.6.0
- zarr==2.18.2
- zipp==3.20.0
- zstandard==0.22.0
prefix: /data/ascher01/uqmmune1/miniconda3/envs/viprs_env
Plink Hyperparameters#
Plink is a tool that allows us to perform clumping and pruning. It also lets us specify the p-value thresholds used on the training data. For each combination of clumping, pruning, and p-value thresholds, a polygenic risk code is generated for each person. Plink takes beta coefficients or OR ratios from the GWAS file without re-estimating those values. Clumping and pruning are performed on the training data using the specified p-value thresholds. The same remaining number of SNPs from the test set is then used to estimate the polygenic risk scores. No separate clumping and pruning are required on the test set.
Details about clumping can be found here, and information about pruning is available here. P-value threshold documentation can be found [here](https://www.cog-genomics.org/plink/2.0/score#:~:text=–q-score-range can,in the third column%2C e.g., for the scorecard.
Pruning Parameters#
Informs Plink that we wish to perform pruning with a window size of 200 variants, sliding across the genome with a step size of 50 variants at a time, and filter out any SNPs with LD ( r^2 ) higher than 0.25.
1. p_window_size = [200]
2. p_slide_size = [50]
3. p_LD_threshold = [0.25]
Clumping Parameters#
The P-value threshold for an SNP to be included. 1 means to include all SNPs for clumping. SNPs having ( r^2 ) higher than 0.1 with the index SNPs will be removed. SNPs within 200k of the index SNP are considered for clumping.
1. clump_p1 = [1]
2. clump_r2 = [0.1]
3. clump_kb = [200]
Score Parameters#
–q-score-range can be used to apply –score too many variants subsets at once, based on, e.g., p-value ranges.
The “range file” should have range labels in the first column, p-value lower bounds in the second column, and upper bounds in the third column, e.g.
1. pv_1 0.00 0.01
2. pv_2 0.00 0.20
PCA#
Pca also affects the results evident from the initial analysis; however, including more PCA overfits the model.
Kindly note that the number of p-values to be considered varies, and the actual p-value also depends on the dataset. Moreover, after clumping, pruning, and p-value threshold, the number of SNPs in each fold can vary.
GWAS file processing for Plink for viprs-simple#
Convert OR to betas.
import os
import pandas as pd
import numpy as np
import sys
#filedirec = sys.argv[1]
filedirec = "SampleData1"
#filedirec = "asthma_19"
#filedirec = "migraine_0"
def check_phenotype_is_binary_or_continous(filedirec):
# Read the processed quality controlled file for a phenotype
df = pd.read_csv(filedirec+os.sep+filedirec+'_QC.fam',sep="\s+",header=None)
column_values = df[5].unique()
if len(set(column_values)) == 2:
return "Binary"
else:
return "Continous"
# Read the GWAS file.
GWAS = filedirec + os.sep + filedirec+".gz"
df = pd.read_csv(GWAS,compression= "gzip",sep="\s+")
if "BETA" in df.columns.to_list():
# For Continous Phenotype.
df = df[['CHR', 'BP', 'SNP', 'A1', 'A2', 'N', 'SE', 'P', 'BETA', 'INFO', 'MAF']]
else:
df["BETA"] = np.log(df["OR"])
df = df[['CHR', 'BP', 'SNP', 'A1', 'A2', 'N', 'SE', 'P', 'BETA', 'INFO', 'MAF']]
df = df.rename(columns={
'BP': 'POS',
'MAF': 'AF1'
})
df = df[['CHR', 'SNP', 'POS', 'A1', 'A2', 'N', 'AF1', 'BETA', 'SE', 'P']]
N = df["N"].mean()
print(df.head())
df.to_csv(filedirec + os.sep +filedirec+"viprs.txt",sep="\t",index=False)
print(df.head().to_markdown())
print("Length of DataFrame!",len(df))
CHR SNP POS A1 A2 N AF1 BETA SE \
0 1 rs3131962 756604 A G 388028 0.369390 -0.002115 0.003017
1 1 rs12562034 768448 A G 388028 0.336846 0.000687 0.003295
2 1 rs4040617 779322 G A 388028 0.377368 -0.002399 0.003033
3 1 rs79373928 801536 G T 388028 0.483212 0.002034 0.008413
4 1 rs11240779 808631 G A 388028 0.450410 0.001307 0.002428
P
0 0.483171
1 0.834808
2 0.428970
3 0.808999
4 0.590265
| | CHR | SNP | POS | A1 | A2 | N | AF1 | BETA | SE | P |
|---:|------:|:-----------|-------:|:-----|:-----|-------:|---------:|------------:|-----------:|---------:|
| 0 | 1 | rs3131962 | 756604 | A | G | 388028 | 0.36939 | -0.00211532 | 0.00301666 | 0.483171 |
| 1 | 1 | rs12562034 | 768448 | A | G | 388028 | 0.336846 | 0.00068708 | 0.00329472 | 0.834808 |
| 2 | 1 | rs4040617 | 779322 | G | A | 388028 | 0.377368 | -0.00239932 | 0.00303344 | 0.42897 |
| 3 | 1 | rs79373928 | 801536 | G | T | 388028 | 0.483212 | 0.00203363 | 0.00841324 | 0.808999 |
| 4 | 1 | rs11240779 | 808631 | G | A | 388028 | 0.45041 | 0.00130747 | 0.00242821 | 0.590265 |
Length of DataFrame! 499617
Define Hyperparameters#
Define hyperparameters to be optimized and set initial values.
Extract Valid SNPs from Clumped File#
For Windows, download gwak, and for Linux, the awk command is sufficient. For Windows, GWAK is required. You can download it from here. Get it and place it in the same directory.
Execution Path#
At this stage, we have the genotype training data newtrainfilename = "train_data.QC" and genotype test data newtestfilename = "test_data.QC".
We modified the following variables:
filedirec = "SampleData1"orfiledirec = sys.argv[1]foldnumber = "0"orfoldnumber = sys.argv[2]for HPC.
Only these two variables can be modified to execute the code for specific data and specific folds. Though the code can be executed separately for each fold on HPC and separately for each dataset, it is recommended to execute it for multiple diseases and one fold at a time. Here’s the corrected text in Markdown format:
P-values#
PRS calculation relies on P-values. SNPs with low P-values, indicating a high degree of association with a specific trait, are considered for calculation.
You can modify the code below to consider a specific set of P-values and save the file in the same format.
We considered the following parameters:
Minimum P-value:
1e-10Maximum P-value:
1.0Minimum exponent:
10(Minimum P-value in exponent)Number of intervals:
100(Number of intervals to be considered)
The code generates an array of logarithmically spaced P-values:
import numpy as np
import os
minimumpvalue = 10 # Minimum exponent for P-values
numberofintervals = 100 # Number of intervals to be considered
allpvalues = np.logspace(-minimumpvalue, 0, numberofintervals, endpoint=True) # Generating an array of logarithmically spaced P-values
print("Minimum P-value:", allpvalues[0])
print("Maximum P-value:", allpvalues[-1])
count = 1
with open(os.path.join(folddirec, 'range_list'), 'w') as file:
for value in allpvalues:
file.write(f'pv_{value} 0 {value}\n') # Writing range information to the 'range_list' file
count += 1
pvaluefile = os.path.join(folddirec, 'range_list')
In this code:
minimumpvaluedefines the minimum exponent for P-values.numberofintervalsspecifies how many intervals to consider.allpvaluesgenerates an array of P-values spaced logarithmically.The script writes these P-values to a file named
range_listin the specified directory.
from operator import index
import pandas as pd
import numpy as np
import os
import subprocess
import sys
import pandas as pd
import statsmodels.api as sm
import pandas as pd
from sklearn.metrics import roc_auc_score, confusion_matrix
from statsmodels.stats.contingency_tables import mcnemar
def create_directory(directory):
"""Function to create a directory if it doesn't exist."""
if not os.path.exists(directory): # Checking if the directory doesn't exist
os.makedirs(directory) # Creating the directory if it doesn't exist
return directory # Returning the created or existing directory
#foldnumber = sys.argv[1]
foldnumber = "0" # Setting 'foldnumber' to "0"
folddirec = filedirec + os.sep + "Fold_" + foldnumber # Creating a directory path for the specific fold
trainfilename = "train_data" # Setting the name of the training data file
newtrainfilename = "train_data.QC" # Setting the name of the new training data file
testfilename = "test_data" # Setting the name of the test data file
newtestfilename = "test_data.QC" # Setting the name of the new test data file
# Number of PCA to be included as a covariate.
numberofpca = ["6"] # Setting the number of PCA components to be included
# Clumping parameters.
clump_p1 = [1] # List containing clump parameter 'p1'
clump_r2 = [0.1] # List containing clump parameter 'r2'
clump_kb = [200] # List containing clump parameter 'kb'
# Pruning parameters.
p_window_size = [200] # List containing pruning parameter 'window_size'
p_slide_size = [50] # List containing pruning parameter 'slide_size'
p_LD_threshold = [0.25] # List containing pruning parameter 'LD_threshold'
# Kindly note that the number of p-values to be considered varies, and the actual p-value depends on the dataset as well.
# We will specify the range list here.
minimumpvalue = 10 # Minimum p-value in exponent
numberofintervals = 20 # Number of intervals to be considered
allpvalues = np.logspace(-minimumpvalue, 0, numberofintervals, endpoint=True) # Generating an array of logarithmically spaced p-values
count = 1
with open(folddirec + os.sep + 'range_list', 'w') as file:
for value in allpvalues:
file.write(f'pv_{value} 0 {value}\n') # Writing range information to the 'range_list' file
count = count + 1
pvaluefile = folddirec + os.sep + 'range_list'
# Initializing an empty DataFrame with specified column names
prs_result = pd.DataFrame(columns=["clump_p1", "clump_r2", "clump_kb", "p_window_size", "p_slide_size", "p_LD_threshold",
"pvalue", "numberofpca","numberofvariants","Train_pure_prs", "Train_null_model", "Train_best_model",
"Test_pure_prs", "Test_null_model", "Test_best_model"])
Define Helper Functions#
Perform Clumping and Pruning
Calculate PCA Using Plink
Fit Binary Phenotype and Save Results
Fit Continuous Phenotype and Save Results
import os
import subprocess
import pandas as pd
import statsmodels.api as sm
from sklearn.metrics import explained_variance_score
def perform_clumping_and_pruning_on_individual_data(traindirec, newtrainfilename,numberofpca, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile):
command = [
"./plink",
"--bfile", traindirec+os.sep+newtrainfilename,
"--indep-pairwise", p1_val, p2_val, p3_val,
"--out", traindirec+os.sep+trainfilename
]
subprocess.run(command)
# First perform pruning and then clumping and the pruning.
command = [
"./plink",
"--bfile", traindirec+os.sep+newtrainfilename,
"--clump-p1", c1_val,
"--extract", traindirec+os.sep+trainfilename+".prune.in",
"--clump-r2", c2_val,
"--clump-kb", c3_val,
"--clump", filedirec+os.sep+filedirec+".txt",
"--clump-snp-field", "SNP",
"--clump-field", "P",
"--out", traindirec+os.sep+trainfilename
]
subprocess.run(command)
# Extract the valid SNPs from th clumped file.
# For windows download gwak for linux awk commmand is sufficient.
### For windows require GWAK.
### https://sourceforge.net/projects/gnuwin32/
##3 Get it and place it in the same direc.
#os.system("gawk "+"\""+"NR!=1{print $3}"+"\" "+ traindirec+os.sep+trainfilename+".clumped > "+traindirec+os.sep+trainfilename+".valid.snp")
#print("gawk "+"\""+"NR!=1{print $3}"+"\" "+ traindirec+os.sep+trainfilename+".clumped > "+traindirec+os.sep+trainfilename+".valid.snp")
#Linux:
command = f"awk 'NR!=1{{print $3}}' {traindirec}{os.sep}{trainfilename}.clumped > {traindirec}{os.sep}{trainfilename}.valid.snp"
os.system(command)
command = [
"./plink",
"--make-bed",
"--bfile", traindirec+os.sep+newtrainfilename,
"--indep-pairwise", p1_val, p2_val, p3_val,
"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--out", traindirec+os.sep+newtrainfilename+".clumped.pruned"
]
subprocess.run(command)
command = [
"./plink",
"--make-bed",
"--bfile", traindirec+os.sep+testfilename,
"--indep-pairwise", p1_val, p2_val, p3_val,
"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--out", traindirec+os.sep+testfilename+".clumped.pruned"
]
subprocess.run(command)
def calculate_pca_for_traindata_testdata_for_clumped_pruned_snps(traindirec, newtrainfilename,p):
# Calculate the PRS for the test data using the same set of SNPs and also calculate the PCA.
# Also extract the PCA at this point.
# PCA are calculated afer clumping and pruining.
command = [
"./plink",
"--bfile", folddirec+os.sep+testfilename+".clumped.pruned",
# Select the final variants after clumping and pruning.
"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--pca", p,
"--out", folddirec+os.sep+testfilename
]
subprocess.run(command)
command = [
"./plink",
"--bfile", traindirec+os.sep+newtrainfilename+".clumped.pruned",
# Select the final variants after clumping and pruning.
"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--pca", p,
"--out", traindirec+os.sep+trainfilename
]
subprocess.run(command)
# This function fit the binary model on the PRS.
def fit_binary_phenotype_on_PRS(traindirec, newtrainfilename,p,hyp_search,method,epsilon_steps,pi_steps, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile):
threshold_values = allpvalues
# Merge the covariates, pca and phenotypes.
tempphenotype_train = pd.read_table(traindirec+os.sep+newtrainfilename+".clumped.pruned"+".fam", sep="\s+",header=None)
phenotype_train = pd.DataFrame()
phenotype_train["Phenotype"] = tempphenotype_train[5].values
pcs_train = pd.read_table(traindirec+os.sep+trainfilename+".eigenvec", sep="\s+",header=None, names=["FID", "IID"] + [f"PC{str(i)}" for i in range(1, int(p)+1)])
covariate_train = pd.read_table(traindirec+os.sep+trainfilename+".cov",sep="\s+")
covariate_train.fillna(0, inplace=True)
covariate_train = covariate_train[covariate_train["FID"].isin(pcs_train["FID"].values) & covariate_train["IID"].isin(pcs_train["IID"].values)]
covariate_train['FID'] = covariate_train['FID'].astype(str)
pcs_train['FID'] = pcs_train['FID'].astype(str)
covariate_train['IID'] = covariate_train['IID'].astype(str)
pcs_train['IID'] = pcs_train['IID'].astype(str)
covandpcs_train = pd.merge(covariate_train, pcs_train, on=["FID","IID"])
covandpcs_train.fillna(0, inplace=True)
## Scale the covariates!
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import explained_variance_score
scaler = MinMaxScaler()
normalized_values_train = scaler.fit_transform(covandpcs_train.iloc[:, 2:])
#covandpcs_train.iloc[:, 2:] = normalized_values_test
tempphenotype_test = pd.read_table(traindirec+os.sep+testfilename+".clumped.pruned"+".fam", sep="\s+",header=None)
phenotype_test= pd.DataFrame()
phenotype_test["Phenotype"] = tempphenotype_test[5].values
pcs_test = pd.read_table(traindirec+os.sep+testfilename+".eigenvec", sep="\s+",header=None, names=["FID", "IID"] + [f"PC{str(i)}" for i in range(1, int(p)+1)])
covariate_test = pd.read_table(traindirec+os.sep+testfilename+".cov",sep="\s+")
covariate_test.fillna(0, inplace=True)
covariate_test = covariate_test[covariate_test["FID"].isin(pcs_test["FID"].values) & covariate_test["IID"].isin(pcs_test["IID"].values)]
covariate_test['FID'] = covariate_test['FID'].astype(str)
pcs_test['FID'] = pcs_test['FID'].astype(str)
covariate_test['IID'] = covariate_test['IID'].astype(str)
pcs_test['IID'] = pcs_test['IID'].astype(str)
covandpcs_test = pd.merge(covariate_test, pcs_test, on=["FID","IID"])
covandpcs_test.fillna(0, inplace=True)
normalized_values_test = scaler.transform(covandpcs_test.iloc[:, 2:])
#covandpcs_test.iloc[:, 2:] = normalized_values_test
tempalphas = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
l1weights = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
tempalphas = [0.1]
l1weights = [0.1]
phenotype_train["Phenotype"] = phenotype_train["Phenotype"].replace({1: 0, 2: 1})
phenotype_test["Phenotype"] = phenotype_test["Phenotype"].replace({1: 0, 2: 1})
for tempalpha in tempalphas:
for l1weight in l1weights:
try:
null_model = sm.Logit(phenotype_train["Phenotype"], sm.add_constant(covandpcs_train.iloc[:, 2:])).fit_regularized(alpha=tempalpha, L1_wt=l1weight)
#null_model = sm.Logit(phenotype_train["Phenotype"], sm.add_constant(covandpcs_train.iloc[:, 2:])).fit()
except:
print("XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX")
continue
train_null_predicted = null_model.predict(sm.add_constant(covandpcs_train.iloc[:, 2:]))
from sklearn.metrics import roc_auc_score, confusion_matrix
from sklearn.metrics import r2_score
test_null_predicted = null_model.predict(sm.add_constant(covandpcs_test.iloc[:, 2:]))
global prs_result
for i in threshold_values:
try:
prs_train = pd.read_table(traindirec+os.sep+Name+os.sep+"train_data.pv_"+f"{i}.profile", sep="\s+", usecols=["FID", "IID", "SCORE"])
except:
continue
prs_train['FID'] = prs_train['FID'].astype(str)
prs_train['IID'] = prs_train['IID'].astype(str)
try:
prs_test = pd.read_table(traindirec+os.sep+Name+os.sep+"test_data.pv_"+f"{i}.profile", sep="\s+", usecols=["FID", "IID", "SCORE"])
except:
continue
prs_test['FID'] = prs_test['FID'].astype(str)
prs_test['IID'] = prs_test['IID'].astype(str)
pheno_prs_train = pd.merge(covandpcs_train, prs_train, on=["FID", "IID"])
pheno_prs_test = pd.merge(covandpcs_test, prs_test, on=["FID", "IID"])
try:
model = sm.Logit(phenotype_train["Phenotype"], sm.add_constant(pheno_prs_train.iloc[:, 2:])).fit_regularized(alpha=tempalpha, L1_wt=l1weight)
#model = sm.Logit(phenotype_train["Phenotype"], sm.add_constant(pheno_prs_train.iloc[:, 2:])).fit()
except:
continue
train_best_predicted = model.predict(sm.add_constant(pheno_prs_train.iloc[:, 2:]))
test_best_predicted = model.predict(sm.add_constant(pheno_prs_test.iloc[:, 2:]))
from sklearn.metrics import roc_auc_score, confusion_matrix
prs_result = prs_result._append({
"clump_p1": c1_val,
"clump_r2": c2_val,
"clump_kb": c3_val,
"p_window_size": p1_val,
"p_slide_size": p2_val,
"p_LD_threshold": p3_val,
"pvalue": i,
"numberofpca":p,
"tempalpha":str(tempalpha),
"l1weight":str(l1weight),
"numberofvariants": len(pd.read_csv(traindirec+os.sep+newtrainfilename+".clumped.pruned.bim")),
"hyp_search":hyp_search,
"method":method,
"epsilon_steps":str(epsilon_steps),
"pi_steps":str(epsilon_steps),
"Train_pure_prs":roc_auc_score(phenotype_train["Phenotype"].values,prs_train['SCORE'].values),
"Train_null_model":roc_auc_score(phenotype_train["Phenotype"].values,train_null_predicted.values),
"Train_best_model":roc_auc_score(phenotype_train["Phenotype"].values,train_best_predicted.values),
"Test_pure_prs":roc_auc_score(phenotype_test["Phenotype"].values,prs_test['SCORE'].values),
"Test_null_model":roc_auc_score(phenotype_test["Phenotype"].values,test_null_predicted.values),
"Test_best_model":roc_auc_score(phenotype_test["Phenotype"].values,test_best_predicted.values),
}, ignore_index=True)
prs_result.to_csv(traindirec+os.sep+Name+os.sep+"Results.csv",index=False)
return
# This function fit the binary model on the PRS.
def fit_continous_phenotype_on_PRS(traindirec, newtrainfilename,p,hyp_search,method,epsilon_steps,pi_steps, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile):
threshold_values = allpvalues
# Merge the covariates, pca and phenotypes.
tempphenotype_train = pd.read_table(traindirec+os.sep+newtrainfilename+".clumped.pruned"+".fam", sep="\s+",header=None)
phenotype_train = pd.DataFrame()
phenotype_train["Phenotype"] = tempphenotype_train[5].values
pcs_train = pd.read_table(traindirec+os.sep+trainfilename+".eigenvec", sep="\s+",header=None, names=["FID", "IID"] + [f"PC{str(i)}" for i in range(1, int(p)+1)])
covariate_train = pd.read_table(traindirec+os.sep+trainfilename+".cov",sep="\s+")
covariate_train.fillna(0, inplace=True)
covariate_train = covariate_train[covariate_train["FID"].isin(pcs_train["FID"].values) & covariate_train["IID"].isin(pcs_train["IID"].values)]
covariate_train['FID'] = covariate_train['FID'].astype(str)
pcs_train['FID'] = pcs_train['FID'].astype(str)
covariate_train['IID'] = covariate_train['IID'].astype(str)
pcs_train['IID'] = pcs_train['IID'].astype(str)
covandpcs_train = pd.merge(covariate_train, pcs_train, on=["FID","IID"])
covandpcs_train.fillna(0, inplace=True)
## Scale the covariates!
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import explained_variance_score
scaler = MinMaxScaler()
normalized_values_train = scaler.fit_transform(covandpcs_train.iloc[:, 2:])
#covandpcs_train.iloc[:, 2:] = normalized_values_test
tempphenotype_test = pd.read_table(traindirec+os.sep+testfilename+".clumped.pruned"+".fam", sep="\s+",header=None)
phenotype_test= pd.DataFrame()
phenotype_test["Phenotype"] = tempphenotype_test[5].values
pcs_test = pd.read_table(traindirec+os.sep+testfilename+".eigenvec", sep="\s+",header=None, names=["FID", "IID"] + [f"PC{str(i)}" for i in range(1, int(p)+1)])
covariate_test = pd.read_table(traindirec+os.sep+testfilename+".cov",sep="\s+")
covariate_test.fillna(0, inplace=True)
covariate_test = covariate_test[covariate_test["FID"].isin(pcs_test["FID"].values) & covariate_test["IID"].isin(pcs_test["IID"].values)]
covariate_test['FID'] = covariate_test['FID'].astype(str)
pcs_test['FID'] = pcs_test['FID'].astype(str)
covariate_test['IID'] = covariate_test['IID'].astype(str)
pcs_test['IID'] = pcs_test['IID'].astype(str)
covandpcs_test = pd.merge(covariate_test, pcs_test, on=["FID","IID"])
covandpcs_test.fillna(0, inplace=True)
normalized_values_test = scaler.transform(covandpcs_test.iloc[:, 2:])
#covandpcs_test.iloc[:, 2:] = normalized_values_test
tempalphas = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
l1weights = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
tempalphas = [0.1]
l1weights = [0.1]
#phenotype_train["Phenotype"] = phenotype_train["Phenotype"].replace({1: 0, 2: 1})
#phenotype_test["Phenotype"] = phenotype_test["Phenotype"].replace({1: 0, 2: 1})
for tempalpha in tempalphas:
for l1weight in l1weights:
try:
#null_model = sm.OLS(phenotype_train["Phenotype"], sm.add_constant(covandpcs_train.iloc[:, 2:])).fit_regularized(alpha=tempalpha, L1_wt=l1weight)
null_model = sm.OLS(phenotype_train["Phenotype"], sm.add_constant(covandpcs_train.iloc[:, 2:])).fit()
#null_model = sm.OLS(phenotype_train["Phenotype"], sm.add_constant(covandpcs_train.iloc[:, 2:])).fit()
except:
print("XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX")
continue
train_null_predicted = null_model.predict(sm.add_constant(covandpcs_train.iloc[:, 2:]))
from sklearn.metrics import roc_auc_score, confusion_matrix
from sklearn.metrics import r2_score
test_null_predicted = null_model.predict(sm.add_constant(covandpcs_test.iloc[:, 2:]))
global prs_result
for i in threshold_values:
try:
prs_train = pd.read_table(traindirec+os.sep+Name+os.sep+"train_data.pv_"+f"{i}.profile", sep="\s+", usecols=["FID", "IID", "SCORE"])
except:
continue
prs_train['FID'] = prs_train['FID'].astype(str)
prs_train['IID'] = prs_train['IID'].astype(str)
try:
prs_test = pd.read_table(traindirec+os.sep+Name+os.sep+"test_data.pv_"+f"{i}.profile", sep="\s+", usecols=["FID", "IID", "SCORE"])
except:
continue
prs_test['FID'] = prs_test['FID'].astype(str)
prs_test['IID'] = prs_test['IID'].astype(str)
pheno_prs_train = pd.merge(covandpcs_train, prs_train, on=["FID", "IID"])
pheno_prs_test = pd.merge(covandpcs_test, prs_test, on=["FID", "IID"])
try:
#model = sm.OLS(phenotype_train["Phenotype"], sm.add_constant(pheno_prs_train.iloc[:, 2:])).fit_regularized(alpha=tempalpha, L1_wt=l1weight)
model = sm.OLS(phenotype_train["Phenotype"], sm.add_constant(pheno_prs_train.iloc[:, 2:])).fit()
except:
continue
train_best_predicted = model.predict(sm.add_constant(pheno_prs_train.iloc[:, 2:]))
test_best_predicted = model.predict(sm.add_constant(pheno_prs_test.iloc[:, 2:]))
from sklearn.metrics import roc_auc_score, confusion_matrix
prs_result = prs_result._append({
"clump_p1": c1_val,
"clump_r2": c2_val,
"clump_kb": c3_val,
"p_window_size": p1_val,
"p_slide_size": p2_val,
"p_LD_threshold": p3_val,
"pvalue": i,
"numberofpca":p,
"tempalpha":str(tempalpha),
"l1weight":str(l1weight),
"hyp_search":hyp_search,
"method":method,
"epsilon_steps":str(epsilon_steps),
"pi_steps":str(epsilon_steps),
"Train_pure_prs":explained_variance_score(phenotype_train["Phenotype"],prs_train['SCORE'].values),
"Train_null_model":explained_variance_score(phenotype_train["Phenotype"],train_null_predicted),
"Train_best_model":explained_variance_score(phenotype_train["Phenotype"],train_best_predicted),
"Test_pure_prs":explained_variance_score(phenotype_test["Phenotype"],prs_test['SCORE'].values),
"Test_null_model":explained_variance_score(phenotype_test["Phenotype"],test_null_predicted),
"Test_best_model":explained_variance_score(phenotype_test["Phenotype"],test_best_predicted),
}, ignore_index=True)
prs_result.to_csv(traindirec+os.sep+Name+os.sep+"Results.csv",index=False)
return
# Define a global variable to store results
prs_result = pd.DataFrame()
Handling Missing Genetic Maps Information in Genotype BIM File#
If the genotype BIM file is missing genetic distance, download the genetic maps from the following link:
Error Message:
Genetic distance in centi Morgan (cM) is not set in the genotype file!
Place the downloaded files in the current working directory and execute the following code.
def check_if_bim_file_has_genetic_distance(newtrainfilename):
import os
import pandas as pd
# Define the file path
bimfile_path = os.path.join(folddirec, newtrainfilename+".bim")
# Read the bim file
bimfile = pd.read_csv(bimfile_path, header=None, sep='\s+')
# Check if the third column in bimfile is all zeros
if (bimfile.iloc[:, 2] == 0).all():
# Download files from the specified GitHub repository
allframes = []
for loop in range(1, 2):
temp = f"chr{loop}.OMNI.interpolated_genetic_map"
x = pd.read_csv(temp, header=None, sep="\s+")
allframes.append(x)
# Concatenate allframes into a single DataFrame
allframes_df = pd.concat(allframes, ignore_index=True)
# Determine common SNPs between bimfile and allframes_df
common_snps = bimfile.iloc[:, 1].isin(allframes_df.iloc[:, 0])
# Filter bimfile and allframes_df based on common SNPs
bimfile_filtered = bimfile[common_snps]
allframes_filtered = allframes_df[allframes_df.iloc[:, 0].isin(bimfile.iloc[:, 1])]
# Ensure that both DataFrames have the same length and index before assigning values
# Reset indices if needed
bimfile_filtered.reset_index(drop=True, inplace=True)
allframes_filtered.reset_index(drop=True, inplace=True)
# Make sure both DataFrames have the same length before assignment
if len(bimfile_filtered) == len(allframes_filtered):
# Assign values from allframes_filtered to bimfile_filtered
bimfile_filtered.iloc[:, 2] = allframes_filtered.iloc[:, 2].values
common_snps_file = os.path.join(folddirec, "commonSNPs.txt")
plink_cmd = "./plink"
# Save filtered SNPs to a file
bimfile_filtered.iloc[:, 1].to_csv(common_snps_file, header=False, index=False)
# Construct the PLINK command
plink_command = (
f"{plink_cmd} "
f"-bfile {os.path.join(folddirec,newtrainfilename)} "
f"--extract {common_snps_file} "
f"--make-bed "
f"--out {os.path.join(folddirec, 'train_data_1')}"
)
# Execute the PLINK command
os.system(plink_command)
source_bim = os.path.join(folddirec, 'train_data_1.bim')
source_fam = os.path.join(folddirec, 'train_data_1.fam')
source_bed = os.path.join(folddirec, 'train_data_1.bed')
destination_bim = os.path.join(folddirec, newtrainfilename+ '.bim')
destination_fam = os.path.join(folddirec, newtrainfilename+ '.fam')
destination_bed = os.path.join(folddirec, newtrainfilename+ '.bed')
# Move/rename files
os.rename(source_bim, destination_bim)
os.rename(source_fam, destination_fam)
os.rename(source_bed, destination_bed)
bimfile = pd.read_csv(bimfile_path, header=None, sep='\s+')
print(bimfile.head())
bimfile[2] = allframes_filtered[2].values
print(bimfile.head())
bimfile.to_csv(folddirec+os.sep+newtrainfilename+ '.bim', header=False, index=False, sep='\t')
else:
print("The number of rows in the filtered DataFrames does not match.")
# Print the first few rows and the length of the filtered DataFrame
print(bimfile_filtered.tail())
print(len(bimfile_filtered))
else:
print("bimfile contains the Genetic distance in centi Morgan (cM)")
Execute Viprs-grid#
count=0
def transform_viprs_grid(traindirec, newtrainfilename,numberofpca,tempdirec,
epsilon_steps,
pi_steps,
method,hyp_search,genomewide_option, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile):
# First check if the genotype bim file contains genetic distances or not
# If it does not exist, then add the genetic information.
check_if_bim_file_has_genetic_distance(newtrainfilename)
tempdirec = traindirec+os.sep+tempdirec
create_directory(tempdirec)
ldpath = traindirec+os.sep+"LD"
create_directory(traindirec+os.sep+"LD")
#perform_clumping_and_pruning_on_individual_data(traindirec, newtrainfilename,p, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile)
#newtrainfilename = newtrainfilename+".clumped.pruned"
#testfilename = testfilename+".clumped.pruned"
#clupmedfile = traindirec+os.sep+newtrainfilename+".clump"
#prunedfile = traindirec+os.sep+newtrainfilename+".clumped.pruned"
# Also extract the PCA at this point for both test and training data.
calculate_pca_for_traindata_testdata_for_clumped_pruned_snps(traindirec, newtrainfilename,p)
#Extract p-values from the GWAS file.
# Command for Linux.
os.system("awk "+"\'"+"{print $3,$8}"+"\'"+" ./"+filedirec+os.sep+filedirec+".txt > ./"+traindirec+os.sep+"SNP.pvalue")
# Command for windows.
### For windows get GWAK.
### https://sourceforge.net/projects/gnuwin32/
##3 Get it and place it in the same direc.
#os.system("gawk "+"\""+"{print $3,$8}"+"\""+" ./"+filedirec+os.sep+filedirec+".txt > ./"+traindirec+os.sep+"SNP.pvalue")
#print("gawk "+"\""+"{print $3,$8}"+"\""+" ./"+filedirec+os.sep+filedirec+".txt > ./"+traindirec+os.sep+"SNP.pvalue")
#exit(0)
global count
if count==1:
import numpy as np
import magenpy as mgp
import viprs as vp
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore") # ignore warnings
gdl = mgp.GWADataLoader(bed_files= traindirec+os.sep+newtrainfilename+".clumped.pruned",
sumstats_files=filedirec + os.sep +filedirec+"viprs.txt",
sumstats_format="fastGWA")
NN = len(pd.read_csv(traindirec+os.sep+newtrainfilename+".clumped.pruned.fam"))
# Compute LD using the shrinkage estimator (Wen and Stephens 2010):
gdl.compute_ld("shrinkage",
output_dir=ldpath, # Output directory where the LD matrix will be stored
genetic_map_ne=N, # effective population size (Ne)
genetic_map_sample_size=NN)
count=0
fit_file = os.path.join(tempdirec, "viprs_gwasVIPRS_"+hyp_search+".fit.gz")
csv_file = os.path.join(tempdirec, "gwas.csv" )
# Delete the file if it exists
if os.path.exists(fit_file):
os.remove(fit_file)
pass
# Delete the file if it exists
if os.path.exists(csv_file):
os.remove(csv_file)
pass
# Make train Phenotype file.
tempphenotype_train = pd.read_table(traindirec+os.sep+newtrainfilename+".clumped.pruned"+".fam", sep="\s+",header=None)
phenotype_train = pd.DataFrame()
#phenotype_train["Phenotype"] = tempphenotype_train[[1,2,5].values
phenotype_train = pd.DataFrame({
'FID': tempphenotype_train[0], # Assign the column for FID
'IID': tempphenotype_train[1], # Assign the column for IID
'phenotype': tempphenotype_train[5] # Assign the column for Phenotype
})
phenotype_train.to_csv(traindirec+os.sep+trainfilename+".pheno_viprs",sep="\t",index=False)
command = [
'python',
'viprs/bin/viprs_fit',
'-l', ldpath+"/"+"ld/"+"chr_*",
'-m',method,
'--hyp-search',hyp_search,
'-s', filedirec + os.sep +filedirec+"viprs.txt",
'--output-file', "viprs_gwas",
'--output-dir', tempdirec,
#'--keep-lrld',
#'--genomewide',
'--validation-bfile', newtrainfilename+".clumped.pruned",
'--validation-pheno', traindirec+os.sep+trainfilename+".pheno_viprs",
'--sigma-epsilon-steps',str(epsilon_steps),
'--pi-steps',str(pi_steps),
#'--sigma-epsilon-grid',', '.join([int(element) for element in grid_epsilon]),
#'--sigma-epsilon-grid',str(1)+","+str(2),
#'--pi-grid',str(1)+","+str(2),
#'--pi-grid',', '.join([int(element) for element in grid_pi]),
#'--opt-params',', '.join([str(element) for element in opt_params]),
]
print(" ".join(command))
subprocess.run(command)
print("YES")
# Read the data from the gzip file
data = pd.read_csv(fit_file, sep='\s+', compression='gzip')
import numpy as np
if check_phenotype_is_binary_or_continous(filedirec)=="Binary":
data["VAR_BETA"] = np.exp(data["VAR_BETA"])
else:
pass
# Save the betas to a CSV file
data.iloc[:,[1,3,7]].to_csv(csv_file+"_finalgwas_viprsgrid", index=False,sep="\t")
# Caluclate Plink Score.
command = [
"./plink",
"--bfile", traindirec+os.sep+newtrainfilename+".clumped.pruned",
### SNP column = 3, Effect allele column 1 = 4, OR column=9
"--score", csv_file+"_finalgwas_viprsgrid", "1", "2", "3", "header",
"--q-score-range", traindirec+os.sep+"range_list",traindirec+os.sep+"SNP.pvalue",
"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--out", traindirec+os.sep+Name+os.sep+trainfilename
]
#exit(0)
subprocess.run(command)
command = [
"./plink",
"--bfile", folddirec+os.sep+testfilename+".clumped.pruned",
### SNP column = 3, Effect allele column 1 = 4, Beta column=12
"--score", csv_file+"_finalgwas_viprsgrid", "1", "2", "3", "header",
"--q-score-range", traindirec+os.sep+"range_list",traindirec+os.sep+"SNP.pvalue",
"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--out", folddirec+os.sep+Name+os.sep+testfilename
]
subprocess.run(command)
if check_phenotype_is_binary_or_continous(filedirec)=="Binary":
print("Binary Phenotype!")
fit_binary_phenotype_on_PRS(traindirec, newtrainfilename,p,hyp_search,method,epsilon_steps,pi_steps, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile)
else:
print("Continous Phenotype!")
fit_continous_phenotype_on_PRS(traindirec, newtrainfilename,p,hyp_search,method,epsilon_steps,pi_steps, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile)
methods = ['VIPRS','VIPRSMix']
# VIPRSMix does not work.
#'GS', BO does not work
methods = ['VIPRS']
hyp_searchs = ['BMA']
#sigma_beta_steps_range = [10, 100]
sigma_epsilon_steps_range = [ 10]
pi_steps_range = [ 10]
# hyp_searchs,'BO' does not work as well.
result_directory = "viprs_grid"
# Nested loops to iterate over different parameter values
create_directory(folddirec+os.sep+result_directory)
for p1_val in p_window_size:
for p2_val in p_slide_size:
for p3_val in p_LD_threshold:
for c1_val in clump_p1:
for c2_val in clump_r2:
for c3_val in clump_kb:
for p in numberofpca:
for method in methods:
for hyp_search in hyp_searchs:
for loop in range(0,len(sigma_epsilon_steps_range)):
transform_viprs_grid(folddirec, newtrainfilename, p,"VIPRS_GRID_Results", sigma_epsilon_steps_range[loop],pi_steps_range[loop],method,hyp_search,"", str(p1_val), str(p2_val), str(p3_val), str(c1_val), str(c2_val), str(c3_val), result_directory, pvaluefile)
bimfile contains the Genetic distance in centi Morgan (cM)
PLINK v1.90b7.2 64-bit (11 Dec 2023) www.cog-genomics.org/plink/1.9/
(C) 2005-2023 Shaun Purcell, Christopher Chang GNU General Public License v3
Logging to SampleData1/Fold_0/test_data.log.
Options in effect:
--bfile SampleData1/Fold_0/test_data.clumped.pruned
--extract SampleData1/Fold_0/train_data.valid.snp
--out SampleData1/Fold_0/test_data
--pca 6
63761 MB RAM detected; reserving 31880 MB for main workspace.
38646 variants loaded from .bim file.
95 people (44 males, 51 females) loaded from .fam.
95 phenotype values loaded from .fam.
--extract: 38646 variants remaining.
Using up to 8 threads (change this with --threads).
Before main variant filters, 95 founders and 0 nonfounders present.
Calculating allele frequencies... 10111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485868788899091929394959697989 done.
Total genotyping rate is exactly 1.
38646 variants and 95 people pass filters and QC.
Phenotype data is quantitative.
Relationship matrix calculation complete.
--pca: Results saved to SampleData1/Fold_0/test_data.eigenval and
SampleData1/Fold_0/test_data.eigenvec .
PLINK v1.90b7.2 64-bit (11 Dec 2023) www.cog-genomics.org/plink/1.9/
(C) 2005-2023 Shaun Purcell, Christopher Chang GNU General Public License v3
Logging to SampleData1/Fold_0/train_data.log.
Options in effect:
--bfile SampleData1/Fold_0/train_data.QC.clumped.pruned
--extract SampleData1/Fold_0/train_data.valid.snp
--out SampleData1/Fold_0/train_data
--pca 6
63761 MB RAM detected; reserving 31880 MB for main workspace.
38646 variants loaded from .bim file.
380 people (183 males, 197 females) loaded from .fam.
380 phenotype values loaded from .fam.
--extract: 38646 variants remaining.
Using up to 8 threads (change this with --threads).
Before main variant filters, 380 founders and 0 nonfounders present.
Calculating allele frequencies... 10111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485868788899091929394959697989 done.
Total genotyping rate is exactly 1.
38646 variants and 380 people pass filters and QC.
Phenotype data is quantitative.
Relationship matrix calculation complete.
--pca: Results saved to SampleData1/Fold_0/train_data.eigenval and
SampleData1/Fold_0/train_data.eigenvec .
python viprs/bin/viprs_fit -l SampleData1/Fold_0/LD/ld/chr_* -m VIPRS --hyp-search BMA -s SampleData1/SampleData1viprs.txt --output-file viprs_gwas --output-dir SampleData1/Fold_0/VIPRS_GRID_Results --validation-bfile train_data.QC.clumped.pruned --validation-pheno SampleData1/Fold_0/train_data.pheno_viprs --sigma-epsilon-steps 10 --pi-steps 10
**********************************************
_____
___ _____(_)________ ________________
__ | / /__ / ___ __ \__ ___/__ ___/
__ |/ / _ / __ /_/ /_ / _(__ )
_____/ /_/ _ .___/ /_/ /____/
/_/
Variational Inference of Polygenic Risk Scores
Version: 0.1.2 | Release date: June 2024
Author: Shadi Zabad, McGill University
**********************************************
< Fit VIPRS models to GWAS summary statistics >
--------------------- Parsed arguments ---------------------
-- ld_dir : SampleData1/Fold_0/LD/ld/chr_*
-- sumstats_path : SampleData1/SampleData1viprs.txt
-- output_dir : SampleData1/Fold_0/VIPRS_GRID_Results
-- output_prefix : viprs_gwas
-- validation_bed : train_data.QC.clumped.pruned
-- validation_pheno : SampleData1/Fold_0/train_data.pheno_viprs
-- hyp_search : BMA
-- pi_steps : 10
-- sigma_epsilon_steps : 10
------------- Reading & harmonizing input data -------------
> Reading the training dataset...
Reading LD metadata: 100%|██████████| 22/22 [00:00<00:00, 266.89it/s]
> Filtering long-range LD regions...
> Reading summary statistics...
Harmonizing data: 100%|██████████| 22/22 [00:00<00:00, 24.60it/s]
Chromosome 1 (13888 variants): 0%| | 0/1000 [00:00<?, ?it/s]
---------------------- Model details -----------------------
- Model: VIPRS
- Hyperparameter tuning strategy: Bayesian model averaging
---------------------- Model fitting -----------------------
Chromosome 1 (13888 variants): 100%|██████████| 56/56 [00:01<00:00, 30.79it/s, Best ELBO=-543776.9375, Models converged=100/100]
Chromosome 2 (13354 variants): 100%|██████████| 57/57 [00:01<00:00, 30.48it/s, Best ELBO=-544047.3125, Models converged=100/100]
Chromosome 3 (11665 variants): 100%|██████████| 46/46 [00:01<00:00, 33.44it/s, Best ELBO=-544375.0625, Models converged=100/100]
Chromosome 4 (11041 variants): 100%|██████████| 43/43 [00:01<00:00, 33.04it/s, Best ELBO=-544983.3750, Models converged=100/100]
Chromosome 5 (10529 variants): 100%|██████████| 48/48 [00:01<00:00, 36.18it/s, Best ELBO=-545733.5000, Models converged=100/100]
Chromosome 6 (9591 variants): 100%|██████████| 38/38 [00:00<00:00, 38.11it/s, Best ELBO=-545525.8125, Models converged=100/100]
Chromosome 7 (9317 variants): 100%|██████████| 41/41 [00:01<00:00, 40.03it/s, Best ELBO=-546121.9375, Models converged=100/100]
Chromosome 8 (8436 variants): 100%|██████████| 38/38 [00:00<00:00, 48.69it/s, Best ELBO=-546271.8125, Models converged=100/100]
Chromosome 9 (7768 variants): 100%|██████████| 36/36 [00:00<00:00, 47.98it/s, Best ELBO=-546825.6250, Models converged=100/100]
Chromosome 10 (8758 variants): 100%|██████████| 38/38 [00:00<00:00, 44.70it/s, Best ELBO=-546540.4375, Models converged=100/100]
Chromosome 11 (8336 variants): 100%|██████████| 34/34 [00:00<00:00, 46.97it/s, Best ELBO=-545991.1250, Models converged=100/100]
Chromosome 12 (8081 variants): 100%|██████████| 35/35 [00:00<00:00, 44.52it/s, Best ELBO=-546574.2500, Models converged=100/100]
Chromosome 13 (6350 variants): 100%|██████████| 29/29 [00:00<00:00, 55.69it/s, Best ELBO=-547634.5000, Models converged=100/100]
Chromosome 14 (5742 variants): 100%|██████████| 25/25 [00:00<00:00, 57.12it/s, Best ELBO=-547941.6875, Models converged=100/100]
Chromosome 15 (5569 variants): 100%|██████████| 26/26 [00:00<00:00, 59.52it/s, Best ELBO=-547943.8750, Models converged=100/100]
Chromosome 16 (6069 variants): 100%|██████████| 30/30 [00:00<00:00, 60.00it/s, Best ELBO=-547671.8125, Models converged=100/100]
Chromosome 17 (5723 variants): 100%|██████████| 26/26 [00:00<00:00, 59.38it/s, Best ELBO=-548002.0000, Models converged=100/100]
Chromosome 18 (5578 variants): 100%|██████████| 28/28 [00:00<00:00, 61.55it/s, Best ELBO=-548164.6250, Models converged=100/100]
Chromosome 19 (4364 variants): 100%|██████████| 21/21 [00:00<00:00, 77.53it/s, Best ELBO=-548261.8125, Models converged=100/100]
Chromosome 20 (4858 variants): 100%|██████████| 24/24 [00:00<00:00, 66.66it/s, Best ELBO=-548417.1250, Models converged=100/100]
Chromosome 21 (2811 variants): 100%|██████████| 20/20 [00:00<00:00, 112.71it/s, Best ELBO=-549640.0625, Models converged=100/100]
Chromosome 22 (2831 variants): 100%|██████████| 16/16 [00:00<00:00, 103.80it/s, Best ELBO=-548984.5625, Models converged=100/100]
--------------------------------------------------------------
>>> Writing the inference results to:
SampleData1/Fold_0/VIPRS_GRID_Results
>>> Total Runtime:
0:00:20.079594
YES
PLINK v1.90b7.2 64-bit (11 Dec 2023) www.cog-genomics.org/plink/1.9/
(C) 2005-2023 Shaun Purcell, Christopher Chang GNU General Public License v3
Logging to SampleData1/Fold_0/viprs_grid/train_data.log.
Options in effect:
--bfile SampleData1/Fold_0/train_data.QC.clumped.pruned
--extract SampleData1/Fold_0/train_data.valid.snp
--out SampleData1/Fold_0/viprs_grid/train_data
--q-score-range SampleData1/Fold_0/range_list SampleData1/Fold_0/SNP.pvalue
--score SampleData1/Fold_0/VIPRS_GRID_Results/gwas.csv_finalgwas_viprsgrid 1 2 3 header
63761 MB RAM detected; reserving 31880 MB for main workspace.
38646 variants loaded from .bim file.
380 people (183 males, 197 females) loaded from .fam.
380 phenotype values loaded from .fam.
--extract: 38646 variants remaining.
Using 1 thread (no multithreaded calculations invoked).
Before main variant filters, 380 founders and 0 nonfounders present.
Calculating allele frequencies... 10111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485868788899091929394959697989 done.
Total genotyping rate is exactly 1.
38646 variants and 380 people pass filters and QC.
Phenotype data is quantitative.
--score: 30041 valid predictors loaded.
Warning: 140618 lines skipped in --score file (140618 due to variant ID
mismatch, 0 due to allele code mismatch); see
SampleData1/Fold_0/viprs_grid/train_data.nopred for details.
Warning: 469577 lines skipped in --q-score-range data file.
--score: 20 ranges processed.
Results written to SampleData1/Fold_0/viprs_grid/train_data.*.profile.
PLINK v1.90b7.2 64-bit (11 Dec 2023) www.cog-genomics.org/plink/1.9/
(C) 2005-2023 Shaun Purcell, Christopher Chang GNU General Public License v3
Logging to SampleData1/Fold_0/viprs_grid/test_data.log.
Options in effect:
--bfile SampleData1/Fold_0/test_data.clumped.pruned
--extract SampleData1/Fold_0/train_data.valid.snp
--out SampleData1/Fold_0/viprs_grid/test_data
--q-score-range SampleData1/Fold_0/range_list SampleData1/Fold_0/SNP.pvalue
--score SampleData1/Fold_0/VIPRS_GRID_Results/gwas.csv_finalgwas_viprsgrid 1 2 3 header
63761 MB RAM detected; reserving 31880 MB for main workspace.
38646 variants loaded from .bim file.
95 people (44 males, 51 females) loaded from .fam.
95 phenotype values loaded from .fam.
--extract: 38646 variants remaining.
Using 1 thread (no multithreaded calculations invoked).
Before main variant filters, 95 founders and 0 nonfounders present.
Calculating allele frequencies... 10111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485868788899091929394959697989 done.
Total genotyping rate is exactly 1.
38646 variants and 95 people pass filters and QC.
Phenotype data is quantitative.
--score: 30041 valid predictors loaded.
--score: 20 ranges processed.
Results written to SampleData1/Fold_0/viprs_grid/test_data.*.profile.
Continous Phenotype!
Warning: 140618 lines skipped in --score file (140618 due to variant ID
mismatch, 0 due to allele code mismatch); see
SampleData1/Fold_0/viprs_grid/test_data.nopred for details.
Warning: 469577 lines skipped in --q-score-range data file.
Repeat the process for each fold.#
Change the foldnumber variable.
#foldnumber = sys.argv[1]
foldnumber = "0" # Setting 'foldnumber' to "0"
Or uncomment the following line:
# foldnumber = sys.argv[1]
python viprs-grid.py 0
python viprs-grid.py 1
python viprs-grid.py 2
python viprs-grid.py 3
python viprs-grid.py 4
The following files should exist after the execution:
SampleData1/Fold_0/viprs_grid/Results.csvSampleData1/Fold_1/viprs_grid/Results.csvSampleData1/Fold_2/viprs_grid/Results.csvSampleData1/Fold_3/viprs_grid/Results.csvSampleData1/Fold_4/viprs_grid/Results.csv
Check the results file for each fold.#
import os
# List of file names to check for existence
f = [
"./"+filedirec+"/Fold_0"+os.sep+result_directory+"Results.csv",
"./"+filedirec+"/Fold_1"+os.sep+result_directory+"Results.csv",
"./"+filedirec+"/Fold_2"+os.sep+result_directory+"Results.csv",
"./"+filedirec+"/Fold_3"+os.sep+result_directory+"Results.csv",
"./"+filedirec+"/Fold_4"+os.sep+result_directory+"Results.csv",
]
# Loop through each file name in the list
for loop in range(0,5):
# Check if the file exists in the specified directory for the given fold
if os.path.exists(filedirec+os.sep+"Fold_"+str(loop)+os.sep+result_directory+os.sep+"Results.csv"):
temp = pd.read_csv(filedirec+os.sep+"Fold_"+str(loop)+os.sep+result_directory+os.sep+"Results.csv")
print("Fold_",loop, "Yes, the file exists.")
#print(temp.head())
print("Number of P-values processed: ",len(temp))
# Print a message indicating that the file exists
else:
# Print a message indicating that the file does not exist
print("Fold_",loop, "No, the file does not exist.")
Fold_ 0 Yes, the file exists.
Number of P-values processed: 20
Fold_ 1 Yes, the file exists.
Number of P-values processed: 20
Fold_ 2 Yes, the file exists.
Number of P-values processed: 20
Fold_ 3 Yes, the file exists.
Number of P-values processed: 20
Fold_ 4 Yes, the file exists.
Number of P-values processed: 20
Sum the results for each fold.#
print("We have to ensure when we sum the entries across all Folds, the same rows are merged!")
def sum_and_average_columns(data_frames):
"""Sum and average numerical columns across multiple DataFrames, and keep non-numerical columns unchanged."""
# Initialize DataFrame to store the summed results for numerical columns
summed_df = pd.DataFrame()
non_numerical_df = pd.DataFrame()
for df in data_frames:
# Identify numerical and non-numerical columns
numerical_cols = df.select_dtypes(include=[np.number]).columns
non_numerical_cols = df.select_dtypes(exclude=[np.number]).columns
# Sum numerical columns
if summed_df.empty:
summed_df = pd.DataFrame(0, index=range(len(df)), columns=numerical_cols)
summed_df[numerical_cols] = summed_df[numerical_cols].add(df[numerical_cols], fill_value=0)
# Keep non-numerical columns (take the first non-numerical entry for each column)
if non_numerical_df.empty:
non_numerical_df = df[non_numerical_cols]
else:
non_numerical_df[non_numerical_cols] = non_numerical_df[non_numerical_cols].combine_first(df[non_numerical_cols])
# Divide the summed values by the number of dataframes to get the average
averaged_df = summed_df / len(data_frames)
# Combine numerical and non-numerical DataFrames
result_df = pd.concat([averaged_df, non_numerical_df], axis=1)
return result_df
from functools import reduce
import os
import pandas as pd
from functools import reduce
def find_common_rows(allfoldsframe):
# Define the performance columns that need to be excluded
performance_columns = [
'Train_null_model', 'Train_pure_prs', 'Train_best_model',
'Test_pure_prs', 'Test_null_model', 'Test_best_model'
]
important_columns = [
'clump_p1',
'clump_r2',
'clump_kb',
'p_window_size',
'p_slide_size',
'p_LD_threshold',
'pvalue',
'referencepanel',
'effectsizes',
"hyp_search",
"method",
"epsilon_steps",
"pi_steps",
'numberofpca',
'tempalpha',
'l1weight',
]
# Function to remove performance columns from a DataFrame
def drop_performance_columns(df):
return df.drop(columns=performance_columns, errors='ignore')
def get_important_columns(df ):
existing_columns = [col for col in important_columns if col in df.columns]
if existing_columns:
return df[existing_columns].copy()
else:
return pd.DataFrame()
# Drop performance columns from all DataFrames in the list
allfoldsframe_dropped = [drop_performance_columns(df) for df in allfoldsframe]
# Get the important columns.
allfoldsframe_dropped = [get_important_columns(df) for df in allfoldsframe_dropped]
# Iteratively find common rows and track unique and common rows
common_rows = allfoldsframe_dropped[0]
for i in range(1, len(allfoldsframe_dropped)):
# Get the next DataFrame
next_df = allfoldsframe_dropped[i]
# Count unique rows in the current DataFrame and the next DataFrame
unique_in_common = common_rows.shape[0]
unique_in_next = next_df.shape[0]
# Find common rows between the current common_rows and the next DataFrame
common_rows = pd.merge(common_rows, next_df, how='inner')
# Count the common rows after merging
common_count = common_rows.shape[0]
# Print the unique and common row counts
print(f"Iteration {i}:")
print(f"Unique rows in current common DataFrame: {unique_in_common}")
print(f"Unique rows in next DataFrame: {unique_in_next}")
print(f"Common rows after merge: {common_count}\n")
# Now that we have the common rows, extract these from the original DataFrames
extracted_common_rows_frames = []
for original_df in allfoldsframe:
# Merge the common rows with the original DataFrame, keeping only the rows that match the common rows
extracted_common_rows = pd.merge(common_rows, original_df, how='inner', on=common_rows.columns.tolist())
# Add the DataFrame with the extracted common rows to the list
extracted_common_rows_frames.append(extracted_common_rows)
# Print the number of rows in the common DataFrames
for i, df in enumerate(extracted_common_rows_frames):
print(f"DataFrame {i + 1} with extracted common rows has {df.shape[0]} rows.")
# Return the list of DataFrames with extracted common rows
return extracted_common_rows_frames
# Example usage (assuming allfoldsframe is populated as shown earlier):
allfoldsframe = []
# Loop through each file name in the list
for loop in range(0, 5):
# Check if the file exists in the specified directory for the given fold
file_path = os.path.join(filedirec, "Fold_" + str(loop), result_directory, "Results.csv")
if os.path.exists(file_path):
allfoldsframe.append(pd.read_csv(file_path))
# Print a message indicating that the file exists
print("Fold_", loop, "Yes, the file exists.")
else:
# Print a message indicating that the file does not exist
print("Fold_", loop, "No, the file does not exist.")
# Find the common rows across all folds and return the list of extracted common rows
extracted_common_rows_list = find_common_rows(allfoldsframe)
# Sum the values column-wise
# For string values, do not sum it the values are going to be the same for each fold.
# Only sum the numeric values.
divided_result = sum_and_average_columns(extracted_common_rows_list)
print(divided_result)
We have to ensure when we sum the entries across all Folds, the same rows are merged!
Fold_ 0 Yes, the file exists.
Fold_ 1 Yes, the file exists.
Fold_ 2 Yes, the file exists.
Fold_ 3 Yes, the file exists.
Fold_ 4 Yes, the file exists.
Iteration 1:
Unique rows in current common DataFrame: 20
Unique rows in next DataFrame: 20
Common rows after merge: 20
Iteration 2:
Unique rows in current common DataFrame: 20
Unique rows in next DataFrame: 20
Common rows after merge: 20
Iteration 3:
Unique rows in current common DataFrame: 20
Unique rows in next DataFrame: 20
Common rows after merge: 20
Iteration 4:
Unique rows in current common DataFrame: 20
Unique rows in next DataFrame: 20
Common rows after merge: 20
DataFrame 1 with extracted common rows has 20 rows.
DataFrame 2 with extracted common rows has 20 rows.
DataFrame 3 with extracted common rows has 20 rows.
DataFrame 4 with extracted common rows has 20 rows.
DataFrame 5 with extracted common rows has 20 rows.
clump_p1 clump_r2 clump_kb p_window_size p_slide_size p_LD_threshold \
0 1.0 0.1 200.0 200.0 50.0 0.25
1 1.0 0.1 200.0 200.0 50.0 0.25
2 1.0 0.1 200.0 200.0 50.0 0.25
3 1.0 0.1 200.0 200.0 50.0 0.25
4 1.0 0.1 200.0 200.0 50.0 0.25
5 1.0 0.1 200.0 200.0 50.0 0.25
6 1.0 0.1 200.0 200.0 50.0 0.25
7 1.0 0.1 200.0 200.0 50.0 0.25
8 1.0 0.1 200.0 200.0 50.0 0.25
9 1.0 0.1 200.0 200.0 50.0 0.25
10 1.0 0.1 200.0 200.0 50.0 0.25
11 1.0 0.1 200.0 200.0 50.0 0.25
12 1.0 0.1 200.0 200.0 50.0 0.25
13 1.0 0.1 200.0 200.0 50.0 0.25
14 1.0 0.1 200.0 200.0 50.0 0.25
15 1.0 0.1 200.0 200.0 50.0 0.25
16 1.0 0.1 200.0 200.0 50.0 0.25
17 1.0 0.1 200.0 200.0 50.0 0.25
18 1.0 0.1 200.0 200.0 50.0 0.25
19 1.0 0.1 200.0 200.0 50.0 0.25
pvalue epsilon_steps pi_steps numberofpca tempalpha l1weight \
0 1.000000e-10 10.0 10.0 6.0 0.1 0.1
1 3.359818e-10 10.0 10.0 6.0 0.1 0.1
2 1.128838e-09 10.0 10.0 6.0 0.1 0.1
3 3.792690e-09 10.0 10.0 6.0 0.1 0.1
4 1.274275e-08 10.0 10.0 6.0 0.1 0.1
5 4.281332e-08 10.0 10.0 6.0 0.1 0.1
6 1.438450e-07 10.0 10.0 6.0 0.1 0.1
7 4.832930e-07 10.0 10.0 6.0 0.1 0.1
8 1.623777e-06 10.0 10.0 6.0 0.1 0.1
9 5.455595e-06 10.0 10.0 6.0 0.1 0.1
10 1.832981e-05 10.0 10.0 6.0 0.1 0.1
11 6.158482e-05 10.0 10.0 6.0 0.1 0.1
12 2.069138e-04 10.0 10.0 6.0 0.1 0.1
13 6.951928e-04 10.0 10.0 6.0 0.1 0.1
14 2.335721e-03 10.0 10.0 6.0 0.1 0.1
15 7.847600e-03 10.0 10.0 6.0 0.1 0.1
16 2.636651e-02 10.0 10.0 6.0 0.1 0.1
17 8.858668e-02 10.0 10.0 6.0 0.1 0.1
18 2.976351e-01 10.0 10.0 6.0 0.1 0.1
19 1.000000e+00 10.0 10.0 6.0 0.1 0.1
Train_pure_prs Train_null_model Train_best_model Test_pure_prs \
0 7.335552e-09 0.23001 0.238846 4.832210e-09
1 4.984455e-09 0.23001 0.234638 2.867451e-09
2 3.293943e-09 0.23001 0.233932 5.740120e-10
3 1.645438e-09 0.23001 0.232382 3.775110e-10
4 4.006713e-10 0.23001 0.231678 -1.209743e-09
5 9.556286e-10 0.23001 0.231132 4.730917e-10
6 6.081035e-10 0.23001 0.230504 8.690384e-11
7 -3.663465e-10 0.23001 0.230560 -1.068434e-09
8 -1.015574e-09 0.23001 0.231778 -2.143179e-09
9 -6.150084e-10 0.23001 0.231311 -1.086359e-09
10 -3.750132e-10 0.23001 0.230839 -5.802096e-10
11 -4.190173e-10 0.23001 0.230428 -6.599072e-10
12 -6.217093e-10 0.23001 0.231452 -5.307534e-10
13 -6.136126e-10 0.23001 0.231904 -4.932158e-10
14 -2.466647e-10 0.23001 0.230436 -6.175038e-11
15 -5.933845e-10 0.23001 0.233554 -4.223618e-10
16 -5.279585e-10 0.23001 0.233384 -4.787304e-10
17 -2.547936e-10 0.23001 0.231367 -2.588033e-10
18 -3.338043e-10 0.23001 0.232267 -3.866857e-10
19 -2.921856e-10 0.23001 0.232868 -2.595187e-10
Test_null_model Test_best_model hyp_search method
0 0.118692 0.130959 BMA VIPRS
1 0.118692 0.127939 BMA VIPRS
2 0.118692 0.118721 BMA VIPRS
3 0.118692 0.120634 BMA VIPRS
4 0.118692 0.115066 BMA VIPRS
5 0.118692 0.117965 BMA VIPRS
6 0.118692 0.116258 BMA VIPRS
7 0.118692 0.113701 BMA VIPRS
8 0.118692 0.116023 BMA VIPRS
9 0.118692 0.114314 BMA VIPRS
10 0.118692 0.117254 BMA VIPRS
11 0.118692 0.118060 BMA VIPRS
12 0.118692 0.117377 BMA VIPRS
13 0.118692 0.117439 BMA VIPRS
14 0.118692 0.115314 BMA VIPRS
15 0.118692 0.117962 BMA VIPRS
16 0.118692 0.125627 BMA VIPRS
17 0.118692 0.117832 BMA VIPRS
18 0.118692 0.126938 BMA VIPRS
19 0.118692 0.128166 BMA VIPRS
/tmp/ipykernel_1085643/235367640.py:24: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
non_numerical_df[non_numerical_cols] = non_numerical_df[non_numerical_cols].combine_first(df[non_numerical_cols])
/tmp/ipykernel_1085643/235367640.py:24: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
non_numerical_df[non_numerical_cols] = non_numerical_df[non_numerical_cols].combine_first(df[non_numerical_cols])
/tmp/ipykernel_1085643/235367640.py:24: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
non_numerical_df[non_numerical_cols] = non_numerical_df[non_numerical_cols].combine_first(df[non_numerical_cols])
/tmp/ipykernel_1085643/235367640.py:24: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
non_numerical_df[non_numerical_cols] = non_numerical_df[non_numerical_cols].combine_first(df[non_numerical_cols])
Results#
1. Reporting Based on Best Training Performance:#
One can report the results based on the best performance of the training data. For example, if for a specific combination of hyperparameters, the training performance is high, report the corresponding test performance.
Example code:
df = divided_result.sort_values(by='Train_best_model', ascending=False) print(df.iloc[0].to_markdown())
Binary Phenotypes Result Analysis#
You can find the performance quality for binary phenotype using the following template:
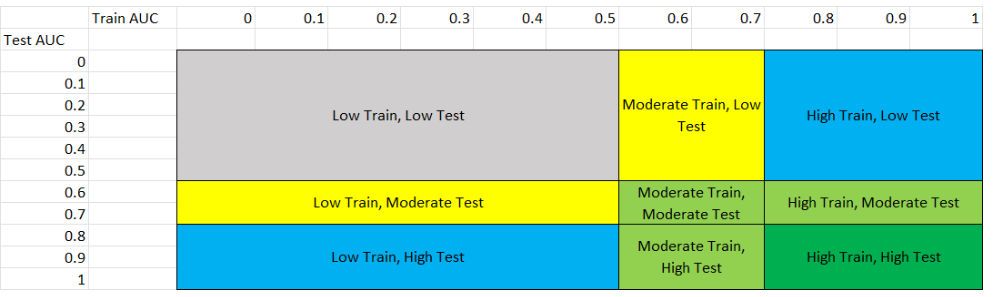
This figure shows the 8 different scenarios that can exist in the results, and the following table explains each scenario.
We classified performance based on the following table:
Performance Level |
Range |
|---|---|
Low Performance |
0 to 0.5 |
Moderate Performance |
0.6 to 0.7 |
High Performance |
0.8 to 1 |
You can match the performance based on the following scenarios:
Scenario |
What’s Happening |
Implication |
|---|---|---|
High Test, High Train |
The model performs well on both training and test datasets, effectively learning the underlying patterns. |
The model is well-tuned, generalizes well, and makes accurate predictions on both datasets. |
High Test, Moderate Train |
The model generalizes well but may not be fully optimized on training data, missing some underlying patterns. |
The model is fairly robust but may benefit from further tuning or more training to improve its learning. |
High Test, Low Train |
An unusual scenario, potentially indicating data leakage or overestimation of test performance. |
The model’s performance is likely unreliable; investigate potential data issues or random noise. |
Moderate Test, High Train |
The model fits the training data well but doesn’t generalize as effectively, capturing only some test patterns. |
The model is slightly overfitting; adjustments may be needed to improve generalization on unseen data. |
Moderate Test, Moderate Train |
The model shows balanced but moderate performance on both datasets, capturing some patterns but missing others. |
The model is moderately fitting; further improvements could be made in both training and generalization. |
Moderate Test, Low Train |
The model underperforms on training data and doesn’t generalize well, leading to moderate test performance. |
The model may need more complexity, additional features, or better training to improve on both datasets. |
Low Test, High Train |
The model overfits the training data, performing poorly on the test set. |
The model doesn’t generalize well; simplifying the model or using regularization may help reduce overfitting. |
Low Test, Low Train |
The model performs poorly on both training and test datasets, failing to learn the data patterns effectively. |
The model is underfitting; it may need more complexity, additional features, or more data to improve performance. |
Recommendations for Publishing Results#
When publishing results, scenarios with moderate train and moderate test performance can be used for complex phenotypes or diseases. However, results showing high train and moderate test, high train and high test, and moderate train and high test are recommended.
For most phenotypes, results typically fall in the moderate train and moderate test performance category.
Continuous Phenotypes Result Analysis#
You can find the performance quality for continuous phenotypes using the following template:
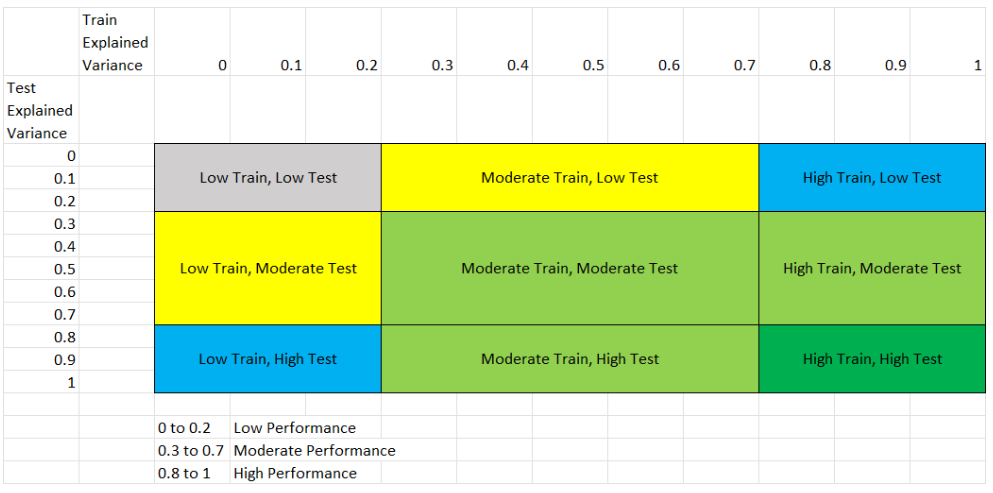
This figure shows the 8 different scenarios that can exist in the results, and the following table explains each scenario.
We classified performance based on the following table:
Performance Level |
Range |
|---|---|
Low Performance |
0 to 0.2 |
Moderate Performance |
0.3 to 0.7 |
High Performance |
0.8 to 1 |
You can match the performance based on the following scenarios:
Scenario |
What’s Happening |
Implication |
|---|---|---|
High Test, High Train |
The model performs well on both training and test datasets, effectively learning the underlying patterns. |
The model is well-tuned, generalizes well, and makes accurate predictions on both datasets. |
High Test, Moderate Train |
The model generalizes well but may not be fully optimized on training data, missing some underlying patterns. |
The model is fairly robust but may benefit from further tuning or more training to improve its learning. |
High Test, Low Train |
An unusual scenario, potentially indicating data leakage or overestimation of test performance. |
The model’s performance is likely unreliable; investigate potential data issues or random noise. |
Moderate Test, High Train |
The model fits the training data well but doesn’t generalize as effectively, capturing only some test patterns. |
The model is slightly overfitting; adjustments may be needed to improve generalization on unseen data. |
Moderate Test, Moderate Train |
The model shows balanced but moderate performance on both datasets, capturing some patterns but missing others. |
The model is moderately fitting; further improvements could be made in both training and generalization. |
Moderate Test, Low Train |
The model underperforms on training data and doesn’t generalize well, leading to moderate test performance. |
The model may need more complexity, additional features, or better training to improve on both datasets. |
Low Test, High Train |
The model overfits the training data, performing poorly on the test set. |
The model doesn’t generalize well; simplifying the model or using regularization may help reduce overfitting. |
Low Test, Low Train |
The model performs poorly on both training and test datasets, failing to learn the data patterns effectively. |
The model is underfitting; it may need more complexity, additional features, or more data to improve performance. |
Recommendations for Publishing Results#
When publishing results, scenarios with moderate train and moderate test performance can be used for complex phenotypes or diseases. However, results showing high train and moderate test, high train and high test, and moderate train and high test are recommended.
For most continuous phenotypes, results typically fall in the moderate train and moderate test performance category.
2. Reporting Generalized Performance:#
One can also report the generalized performance by calculating the difference between the training and test performance, and the sum of the test and training performance. Report the result or hyperparameter combination for which the sum is high and the difference is minimal.
Example code:
df = divided_result.copy() df['Difference'] = abs(df['Train_best_model'] - df['Test_best_model']) df['Sum'] = df['Train_best_model'] + df['Test_best_model'] sorted_df = df.sort_values(by=['Sum', 'Difference'], ascending=[False, True]) print(sorted_df.iloc[0].to_markdown())
3. Reporting Hyperparameters Affecting Test and Train Performance:#
Find the hyperparameters that have more than one unique value and calculate their correlation with the following columns to understand how they are affecting the performance of train and test sets:
Train_null_modelTrain_pure_prsTrain_best_modelTest_pure_prsTest_null_modelTest_best_model
4. Other Analysis#
Once you have the results, you can find how hyperparameters affect the model performance.
Analysis, like overfitting and underfitting, can be performed as well.
The way you are going to report the results can vary.
Results can be visualized, and other patterns in the data can be explored.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib notebook
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
df = divided_result.sort_values(by='Train_best_model', ascending=False)
print("1. Reporting Based on Best Training Performance:\n")
print(df.iloc[0].to_markdown())
df = divided_result.copy()
# Plot Train and Test best models against p-values
plt.figure(figsize=(10, 6))
plt.plot(df['pvalue'], df['Train_best_model'], label='Train_best_model', marker='o', color='royalblue')
plt.plot(df['pvalue'], df['Test_best_model'], label='Test_best_model', marker='o', color='darkorange')
# Highlight the p-value where both train and test are high
best_index = df[['Train_best_model']].sum(axis=1).idxmax()
best_pvalue = df.loc[best_index, 'pvalue']
best_train = df.loc[best_index, 'Train_best_model']
best_test = df.loc[best_index, 'Test_best_model']
# Use dark colors for the circles
plt.scatter(best_pvalue, best_train, color='darkred', s=100, label=f'Best Performance (Train)', edgecolor='black', zorder=5)
plt.scatter(best_pvalue, best_test, color='darkblue', s=100, label=f'Best Performance (Test)', edgecolor='black', zorder=5)
# Annotate the best performance with p-value, train, and test values
plt.text(best_pvalue, best_train, f'p={best_pvalue:.4g}\nTrain={best_train:.4g}', ha='right', va='bottom', fontsize=9, color='darkred')
plt.text(best_pvalue, best_test, f'p={best_pvalue:.4g}\nTest={best_test:.4g}', ha='right', va='top', fontsize=9, color='darkblue')
# Calculate Difference and Sum
df['Difference'] = abs(df['Train_best_model'] - df['Test_best_model'])
df['Sum'] = df['Train_best_model'] + df['Test_best_model']
# Sort the DataFrame
sorted_df = df.sort_values(by=['Sum', 'Difference'], ascending=[False, True])
#sorted_df = df.sort_values(by=[ 'Difference','Sum'], ascending=[ True,False])
# Highlight the general performance
general_index = sorted_df.index[0]
general_pvalue = sorted_df.loc[general_index, 'pvalue']
general_train = sorted_df.loc[general_index, 'Train_best_model']
general_test = sorted_df.loc[general_index, 'Test_best_model']
plt.scatter(general_pvalue, general_train, color='darkgreen', s=150, label='General Performance (Train)', edgecolor='black', zorder=6)
plt.scatter(general_pvalue, general_test, color='darkorange', s=150, label='General Performance (Test)', edgecolor='black', zorder=6)
# Annotate the general performance with p-value, train, and test values
plt.text(general_pvalue, general_train, f'p={general_pvalue:.4g}\nTrain={general_train:.4g}', ha='left', va='bottom', fontsize=9, color='darkgreen')
plt.text(general_pvalue, general_test, f'p={general_pvalue:.4g}\nTest={general_test:.4g}', ha='left', va='top', fontsize=9, color='darkorange')
# Add labels and legend
plt.xlabel('p-value')
plt.ylabel('Model Performance')
plt.title('Train vs Test Best Models')
plt.legend()
plt.show()
print("2. Reporting Generalized Performance:\n")
df = divided_result.copy()
df['Difference'] = abs(df['Train_best_model'] - df['Test_best_model'])
df['Sum'] = df['Train_best_model'] + df['Test_best_model']
sorted_df = df.sort_values(by=['Sum', 'Difference'], ascending=[False, True])
print(sorted_df.iloc[0].to_markdown())
print("3. Reporting the correlation of hyperparameters and the performance of 'Train_null_model', 'Train_pure_prs', 'Train_best_model', 'Test_pure_prs', 'Test_null_model', and 'Test_best_model':\n")
print("3. For string hyperparameters, we used one-hot encoding to find the correlation between string hyperparameters and 'Train_null_model', 'Train_pure_prs', 'Train_best_model', 'Test_pure_prs', 'Test_null_model', and 'Test_best_model'.")
print("3. We performed this analysis for those hyperparameters that have more than one unique value.")
correlation_columns = [
'Train_null_model', 'Train_pure_prs', 'Train_best_model',
'Test_pure_prs', 'Test_null_model', 'Test_best_model'
]
hyperparams = [col for col in divided_result.columns if len(divided_result[col].unique()) > 1]
hyperparams = list(set(hyperparams+correlation_columns))
# Separate numeric and string columns
numeric_hyperparams = [col for col in hyperparams if pd.api.types.is_numeric_dtype(divided_result[col])]
string_hyperparams = [col for col in hyperparams if pd.api.types.is_string_dtype(divided_result[col])]
# Encode string columns using one-hot encoding
divided_result_encoded = pd.get_dummies(divided_result, columns=string_hyperparams)
# Combine numeric hyperparams with the new one-hot encoded columns
encoded_columns = [col for col in divided_result_encoded.columns if col.startswith(tuple(string_hyperparams))]
hyperparams = numeric_hyperparams + encoded_columns
# Calculate correlations
correlations = divided_result_encoded[hyperparams].corr()
# Display correlation of hyperparameters with train/test performance columns
hyperparam_correlations = correlations.loc[hyperparams, correlation_columns]
hyperparam_correlations = hyperparam_correlations.fillna(0)
# Plotting the correlation heatmap
plt.figure(figsize=(12, 8))
ax = sns.heatmap(hyperparam_correlations, annot=True, cmap='viridis', fmt='.2f', cbar=True)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90, ha='right')
# Rotate y-axis labels to horizontal
#ax.set_yticklabels(ax.get_yticklabels(), rotation=0, va='center')
plt.title('Correlation of Hyperparameters with Train/Test Performance')
plt.show()
sns.set_theme(style="whitegrid") # Choose your preferred style
pairplot = sns.pairplot(divided_result_encoded[hyperparams],hue = 'Test_best_model', palette='viridis')
# Adjust the figure size
pairplot.fig.set_size_inches(15, 15) # You can adjust the size as needed
for ax in pairplot.axes.flatten():
ax.set_xlabel(ax.get_xlabel(), rotation=90, ha='right') # X-axis labels vertical
#ax.set_ylabel(ax.get_ylabel(), rotation=0, va='bottom') # Y-axis labels horizontal
# Show the plot
plt.show()
1. Reporting Based on Best Training Performance:
| | 0 |
|:-----------------|:-----------------------|
| clump_p1 | 1.0 |
| clump_r2 | 0.1 |
| clump_kb | 200.0 |
| p_window_size | 200.0 |
| p_slide_size | 50.0 |
| p_LD_threshold | 0.25 |
| pvalue | 1e-10 |
| epsilon_steps | 10.0 |
| pi_steps | 10.0 |
| numberofpca | 6.0 |
| tempalpha | 0.1 |
| l1weight | 0.1 |
| Train_pure_prs | 7.335552454357242e-09 |
| Train_null_model | 0.23001030414198947 |
| Train_best_model | 0.2388455914418312 |
| Test_pure_prs | 4.8322102541575875e-09 |
| Test_null_model | 0.11869244971793831 |
| Test_best_model | 0.1309588452498264 |
| hyp_search | BMA |
| method | VIPRS |

2. Reporting Generalized Performance:
| | 0 |
|:-----------------|:-----------------------|
| clump_p1 | 1.0 |
| clump_r2 | 0.1 |
| clump_kb | 200.0 |
| p_window_size | 200.0 |
| p_slide_size | 50.0 |
| p_LD_threshold | 0.25 |
| pvalue | 1e-10 |
| epsilon_steps | 10.0 |
| pi_steps | 10.0 |
| numberofpca | 6.0 |
| tempalpha | 0.1 |
| l1weight | 0.1 |
| Train_pure_prs | 7.335552454357242e-09 |
| Train_null_model | 0.23001030414198947 |
| Train_best_model | 0.2388455914418312 |
| Test_pure_prs | 4.8322102541575875e-09 |
| Test_null_model | 0.11869244971793831 |
| Test_best_model | 0.1309588452498264 |
| hyp_search | BMA |
| method | VIPRS |
| Difference | 0.1078867461920048 |
| Sum | 0.36980443669165763 |
3. Reporting the correlation of hyperparameters and the performance of 'Train_null_model', 'Train_pure_prs', 'Train_best_model', 'Test_pure_prs', 'Test_null_model', and 'Test_best_model':
3. For string hyperparameters, we used one-hot encoding to find the correlation between string hyperparameters and 'Train_null_model', 'Train_pure_prs', 'Train_best_model', 'Test_pure_prs', 'Test_null_model', and 'Test_best_model'.
3. We performed this analysis for those hyperparameters that have more than one unique value.

