LDpred-funct#
LDpred-funct uses functional annotation to improve prediction. It leverages LDSC to calculate heritability.
Installation#
First, ensure you have Python 2 installed. You can create a Python 2.7 environment using conda:
conda create -n mypython2env python=2.7
You also need to install the required packages: h5py, scipy, and libplinkio. You can install libplinkio using pip (see the pip quickstart guide):
pip install plinkio
Next, clone the LDpred-funct repository:
git clone https://github.com/carlaml/LDpred-funct.git
Heritability Estimation#
To estimate per-SNP heritability inferred using S-LDSC, you’ll need files from the [baselineLD model](https://console.cloud.google.com/storage/browser/broad-alkesgroup-public-requester-pays/LDSCORE/baseline_v1.1_hg38_annots?pageState=(“StorageObjectListTable”:(“f”:”%255B%255D”)).
Download the files from the [baselineLD model](https://console.cloud.google.com/storage/browser/broad-alkesgroup-public-requester-pays/LDSCORE/baseline_v1.1_hg38_annots?pageState=(“StorageObjectListTable”:(“f”:”%255B%255D”)) and place them in the LDSCFILES folder within the current working directory where this notebook or code is located.
Hyperparameters#
LDpred-funct offers multiple hyperparameters, but we considered the following:
hapmapmodels =
["hapmap", "full"]:hapmaprestricts SNPs to HapMap only, which is not recommended for datasets with a limited number of SNPs.fullconsiders all SNPs.ldpredbins =
["2", "10"]: This represents the bin size used by LDpred-funct.
For more details, visit the LDpred-funct GitHub repository.
Important Note#
Important note: If the number of variants between the GWAS and bfile is limited, the code may not work properly. In such scenarios, please review the logs.
GWAS File Processing for LDpred-funct#
LDpred-funct requires the GWAS file in a specific format as:
Summary statistics file. Please check that the summary statistics contains a column for each of the following fields (header is important here, important fields are highlighted in bold font, the order of the columns is not important). carlaml/LDpred-funct
CHR: Chromosome
SNP: SNP ID
BP: Physical position (base-pair)
A1: Minor allele name (based on whole sample)
A2: Major allele name
P: Asymptotic p-value
BETA: Effect size
Z: Z-score (default). If instead of Z-score the Chi-square statistic is provided, use the flag –chisq, and CHISQ as the column field.
LDSC requires the GWAS in a specific format, so we will generate two GWAS files: one for LDSC to calculate heritability and another for LDpred-funct to calculate PRS. bulik/ldsc
Example GWAS format for LDSC:
MarkerName |
Allele1 |
Allele2 |
Freq.Allele1.HapMapCEU |
p |
N |
|---|---|---|---|---|---|
rs10 |
a |
c |
0.0333 |
0.708 |
80566 |
rs1000000 |
g |
a |
0.6333 |
0.506 |
123865 |
rs10000010 |
c |
t |
0.425 |
0.736 |
123827 |
rs10000012 |
c |
g |
0.8083 |
0.042 |
123809 |
Note For both binary and continouse phenotypes, we considered BETAS and convert OR to BETAS.
Note Download LDSC bulik/ldsc
To download and set up LDSC (Linkage Disequilibrium Score Regression), follow these steps:
Open your terminal and run the following command:
git clone https://github.com/bulik/ldsc.git
Download the LDSC files required for heritability calculation and store them in the LDSCFILES/ directory.
w_hm3.snplist.bz2
Download from: w_hm3.snplist.bz2
baselineLD
Download from: baselineLD
Ensure that you store the downloaded files in the LDSCFILES/ directory.
It should have the following files.
.
├── baseline
│ ├── baselineLD.10.annot.gz
│ ├── baselineLD.10.l2.ldscore.gz
│ ├── baselineLD.10.l2.M
│ ├── baselineLD.10.l2.M_5_50
│ ├── baselineLD.10.log
│ ├── baselineLD.11.annot.gz
│ ├── baselineLD.11.l2.ldscore.gz
│ ├── baselineLD.11.l2.M
│ ├── baselineLD.11.l2.M_5_50
│ ├── baselineLD.11.log
│ ├── baselineLD.12.annot.gz
│ ├── baselineLD.12.l2.ldscore.gz
│ ├── baselineLD.12.l2.M
│ ├── baselineLD.12.l2.M_5_50
│ ├── baselineLD.12.log
│ ├── baselineLD.13.annot.gz
│ ├── baselineLD.13.l2.ldscore.gz
│ ├── baselineLD.13.l2.M
│ ├── baselineLD.13.l2.M_5_50
│ ├── baselineLD.13.log
│ ├── baselineLD.14.annot.gz
│ ├── baselineLD.14.l2.ldscore.gz
│ ├── baselineLD.14.l2.M
│ ├── baselineLD.14.l2.M_5_50
│ ├── baselineLD.14.log
│ ├── baselineLD.15.annot.gz
│ ├── baselineLD.15.l2.ldscore.gz
│ ├── baselineLD.15.l2.M
│ ├── baselineLD.15.l2.M_5_50
│ ├── baselineLD.15.log
│ ├── baselineLD.16.annot.gz
│ ├── baselineLD.16.l2.ldscore.gz
│ ├── baselineLD.16.l2.M
│ ├── baselineLD.16.l2.M_5_50
│ ├── baselineLD.16.log
│ ├── baselineLD.17.annot.gz
│ ├── baselineLD.17.l2.ldscore.gz
│ ├── baselineLD.17.l2.M
│ ├── baselineLD.17.l2.M_5_50
│ ├── baselineLD.17.log
│ ├── baselineLD.18.annot.gz
│ ├── baselineLD.18.l2.ldscore.gz
│ ├── baselineLD.18.l2.M
│ ├── baselineLD.18.l2.M_5_50
│ ├── baselineLD.18.log
│ ├── baselineLD.19.annot.gz
│ ├── baselineLD.19.l2.ldscore.gz
│ ├── baselineLD.19.l2.M
│ ├── baselineLD.19.l2.M_5_50
│ ├── baselineLD.19.log
│ ├── baselineLD.1.annot.gz
│ ├── baselineLD.1.l2.ldscore.gz
│ ├── baselineLD.1.l2.M
│ ├── baselineLD.1.l2.M_5_50
│ ├── baselineLD.1.log
│ ├── baselineLD.20.annot.gz
│ ├── baselineLD.20.l2.ldscore.gz
│ ├── baselineLD.20.l2.M
│ ├── baselineLD.20.l2.M_5_50
│ ├── baselineLD.20.log
│ ├── baselineLD.21.annot.gz
│ ├── baselineLD.21.l2.ldscore.gz
│ ├── baselineLD.21.l2.M
│ ├── baselineLD.21.l2.M_5_50
│ ├── baselineLD.21.log
│ ├── baselineLD.22.annot.gz
│ ├── baselineLD.22.l2.ldscore.gz
│ ├── baselineLD.22.l2.M
│ ├── baselineLD.22.l2.M_5_50
│ ├── baselineLD.22.log
│ ├── baselineLD.2.annot.gz
│ ├── baselineLD.2.l2.ldscore.gz
│ ├── baselineLD.2.l2.M
│ ├── baselineLD.2.l2.M_5_50
│ ├── baselineLD.2.log
│ ├── baselineLD.3.annot.gz
│ ├── baselineLD.3.l2.ldscore.gz
│ ├── baselineLD.3.l2.M
│ ├── baselineLD.3.l2.M_5_50
│ ├── baselineLD.3.log
│ ├── baselineLD.4.annot.gz
│ ├── baselineLD.4.l2.ldscore.gz
│ ├── baselineLD.4.l2.M
│ ├── baselineLD.4.l2.M_5_50
│ ├── baselineLD.4.log
│ ├── baselineLD.5.annot.gz
│ ├── baselineLD.5.l2.ldscore.gz
│ ├── baselineLD.5.l2.M
│ ├── baselineLD.5.l2.M_5_50
│ ├── baselineLD.5.log
│ ├── baselineLD.6.annot.gz
│ ├── baselineLD.6.l2.ldscore.gz
│ ├── baselineLD.6.l2.M
│ ├── baselineLD.6.l2.M_5_50
│ ├── baselineLD.6.log
│ ├── baselineLD.7.annot.gz
│ ├── baselineLD.7.l2.ldscore.gz
│ ├── baselineLD.7.l2.M
│ ├── baselineLD.7.l2.M_5_50
│ ├── baselineLD.7.log
│ ├── baselineLD.8.annot.gz
│ ├── baselineLD.8.l2.ldscore.gz
│ ├── baselineLD.8.l2.M
│ ├── baselineLD.8.l2.M_5_50
│ ├── baselineLD.8.log
│ ├── baselineLD.9.annot.gz
│ ├── baselineLD.9.l2.ldscore.gz
│ ├── baselineLD.9.l2.M
│ ├── baselineLD.9.l2.M_5_50
│ └── baselineLD.9.log
├── freq
│ ├── 1000G.EUR.QC.10.frq
│ ├── 1000G.EUR.QC.11.frq
│ ├── 1000G.EUR.QC.12.frq
│ ├── 1000G.EUR.QC.13.frq
│ ├── 1000G.EUR.QC.14.frq
│ ├── 1000G.EUR.QC.15.frq
│ ├── 1000G.EUR.QC.16.frq
│ ├── 1000G.EUR.QC.17.frq
│ ├── 1000G.EUR.QC.18.frq
│ ├── 1000G.EUR.QC.19.frq
│ ├── 1000G.EUR.QC.1.frq
│ ├── 1000G.EUR.QC.20.frq
│ ├── 1000G.EUR.QC.21.frq
│ ├── 1000G.EUR.QC.22.frq
│ ├── 1000G.EUR.QC.2.frq
│ ├── 1000G.EUR.QC.3.frq
│ ├── 1000G.EUR.QC.4.frq
│ ├── 1000G.EUR.QC.5.frq
│ ├── 1000G.EUR.QC.6.frq
│ ├── 1000G.EUR.QC.7.frq
│ ├── 1000G.EUR.QC.8.frq
│ └── 1000G.EUR.QC.9.frq
├── weights
│ ├── weights.10.l2.ldscore.gz
│ ├── weights.11.l2.ldscore.gz
│ ├── weights.12.l2.ldscore.gz
│ ├── weights.13.l2.ldscore.gz
│ ├── weights.14.l2.ldscore.gz
│ ├── weights.15.l2.ldscore.gz
│ ├── weights.16.l2.ldscore.gz
│ ├── weights.17.l2.ldscore.gz
│ ├── weights.18.l2.ldscore.gz
│ ├── weights.19.l2.ldscore.gz
│ ├── weights.1.l2.ldscore.gz
│ ├── weights.20.l2.ldscore.gz
│ ├── weights.21.l2.ldscore.gz
│ ├── weights.22.l2.ldscore.gz
│ ├── weights.2.l2.ldscore.gz
│ ├── weights.3.l2.ldscore.gz
│ ├── weights.4.l2.ldscore.gz
│ ├── weights.5.l2.ldscore.gz
│ ├── weights.6.l2.ldscore.gz
│ ├── weights.7.l2.ldscore.gz
│ ├── weights.8.l2.ldscore.gz
│ └── weights.9.l2.ldscore.gz
└── w_hm3.snplist.bz2
3 directories, 155 files
import os
import pandas as pd
import numpy as np
from scipy.stats import norm
def check_phenotype_is_binary_or_continous(filedirec):
# Read the processed quality controlled file for a phenotype
df = pd.read_csv(filedirec+os.sep+filedirec+'_QC.fam',sep="\s+",header=None)
column_values = df[5].unique()
if len(set(column_values)) == 2:
return "Binary"
else:
return "Continous"
filedirec = "SampleData1"
#filedirec = "asthma_19"
#filedirec = "migraine_0"
GWAS = filedirec + os.sep + filedirec+".gz"
df = pd.read_csv(GWAS,compression= "gzip",sep="\s+")
if "BETA" in df.columns.to_list():
print("Same")
pass
else:
df["BETA"] = np.log(df["OR"])
print("transformed")
df_transformed = pd.DataFrame({
'MarkerName': df['SNP'],
'Allele1': df['A1'],
'Allele2': df['A2'],
'Freq.Allele1.HapMapCEU': df['MAF'],
'p': df['P'],
'N': df['N']
})
output_file = filedirec+os.sep+"LDpred_funct_LDSC.txt"
df_transformed.to_csv(output_file,sep="\t",index=False)
print(df_transformed.head())
GWAS = filedirec + os.sep + filedirec+".gz"
df = pd.read_csv(GWAS,compression= "gzip",sep="\s+")
if "BETA" in df.columns.to_list():
pass
else:
df["BETA"] = np.log(df["OR"])
df_transformed = pd.DataFrame({
'CHR':df['CHR'],
'SNP': df['SNP'],
'BP':df['BP'],
'A1': df['A1'],
'A2': df['A2'],
'BETA': df['BETA'],
'P': df['P'],
})
# Calculate Z score from P values.
# Kindly note if you know a better way to calculate the Z values, use that method for calculating them.
z_scores = norm.ppf(1 - df_transformed['P'] / 2)
df_transformed['Z'] = z_scores
output_file = filedirec+os.sep+"_LDpred_funct.txt"
df_transformed.to_csv(output_file,sep="\t",index=False)
print(df_transformed.head())
transformed
Allele1 Allele2 Freq.Allele1.HapMapCEU MarkerName N p
0 A G 0.369390 rs3131962 388028 0.483171
1 A G 0.336846 rs12562034 388028 0.834808
2 G A 0.377368 rs4040617 388028 0.428970
3 G T 0.483212 rs79373928 388028 0.808999
4 G A 0.450410 rs11240779 388028 0.590265
A1 A2 BETA BP CHR P SNP Z
0 A G -0.002115 756604 1 0.483171 rs3131962 0.701212
1 A G 0.000687 768448 1 0.834808 rs12562034 0.208539
2 G A -0.002399 779322 1 0.428970 rs4040617 0.790955
3 G T 0.002034 801536 1 0.808999 rs79373928 0.241718
4 G A 0.001307 808631 1 0.590265 rs11240779 0.538452
Define Hyperparameters#
Define hyperparameters to be optimized and set initial values.
Extract Valid SNPs from Clumped File#
For Windows, download gwak, and for Linux, the awk command is sufficient. For Windows, GWAK is required. You can download it from here. Get it and place it in the same directory.
Execution Path#
At this stage, we have the genotype training data newtrainfilename = "train_data.QC" and genotype test data newtestfilename = "test_data.QC".
We modified the following variables:
filedirec = "SampleData1"orfiledirec = sys.argv[1]foldnumber = "0"orfoldnumber = sys.argv[2]for HPC.
Only these two variables can be modified to execute the code for specific data and specific folds. Though the code can be executed separately for each fold on HPC and separately for each dataset, it is recommended to execute it for multiple diseases and one fold at a time. Here’s the corrected text in Markdown format:
P-values#
PRS calculation relies on P-values. SNPs with low P-values, indicating a high degree of association with a specific trait, are considered for calculation.
You can modify the code below to consider a specific set of P-values and save the file in the same format.
We considered the following parameters:
Minimum P-value:
1e-10Maximum P-value:
1.0Minimum exponent:
10(Minimum P-value in exponent)Number of intervals:
100(Number of intervals to be considered)
The code generates an array of logarithmically spaced P-values:
import numpy as np
import os
minimumpvalue = 10 # Minimum exponent for P-values
numberofintervals = 100 # Number of intervals to be considered
allpvalues = np.logspace(-minimumpvalue, 0, numberofintervals, endpoint=True) # Generating an array of logarithmically spaced P-values
print("Minimum P-value:", allpvalues[0])
print("Maximum P-value:", allpvalues[-1])
count = 1
with open(os.path.join(folddirec, 'range_list'), 'w') as file:
for value in allpvalues:
file.write(f'pv_{value} 0 {value}\n') # Writing range information to the 'range_list' file
count += 1
pvaluefile = os.path.join(folddirec, 'range_list')
In this code:
minimumpvaluedefines the minimum exponent for P-values.numberofintervalsspecifies how many intervals to consider.allpvaluesgenerates an array of P-values spaced logarithmically.The script writes these P-values to a file named
range_listin the specified directory.
from operator import index
import pandas as pd
import numpy as np
import os
import subprocess
import sys
import pandas as pd
import statsmodels.api as sm
import pandas as pd
from sklearn.metrics import roc_auc_score, confusion_matrix
from statsmodels.stats.contingency_tables import mcnemar
def create_directory(directory):
"""Function to create a directory if it doesn't exist."""
if not os.path.exists(directory): # Checking if the directory doesn't exist
os.makedirs(directory) # Creating the directory if it doesn't exist
return directory # Returning the created or existing directory
#foldnumber = sys.argv[1]
foldnumber = "0" # Setting 'foldnumber' to "0"
folddirec = filedirec + os.sep + "Fold_" + foldnumber # Creating a directory path for the specific fold
trainfilename = "train_data" # Setting the name of the training data file
newtrainfilename = "train_data.QC" # Setting the name of the new training data file
testfilename = "test_data" # Setting the name of the test data file
newtestfilename = "test_data.QC" # Setting the name of the new test data file
# Number of PCA to be included as a covariate.
numberofpca = ["6"] # Setting the number of PCA components to be included
# Clumping parameters.
clump_p1 = [1] # List containing clump parameter 'p1'
clump_r2 = [0.1] # List containing clump parameter 'r2'
clump_kb = [200] # List containing clump parameter 'kb'
# Pruning parameters.
p_window_size = [200] # List containing pruning parameter 'window_size'
p_slide_size = [50] # List containing pruning parameter 'slide_size'
p_LD_threshold = [0.25] # List containing pruning parameter 'LD_threshold'
# Kindly note that the number of p-values to be considered varies, and the actual p-value depends on the dataset as well.
# We will specify the range list here.
minimumpvalue = 10 # Minimum p-value in exponent
numberofintervals = 20 # Number of intervals to be considered
allpvalues = np.logspace(-minimumpvalue, 0, numberofintervals, endpoint=True) # Generating an array of logarithmically spaced p-values
count = 1
with open(os.path.join(folddirec, 'range_list'), 'w') as file:
for value in allpvalues:
file.write('pv_{} 0 {}\n'.format(float(value), float(value))) # Writing range information to the 'range_list' file
count = count + 1
pvaluefile = folddirec + os.sep + 'range_list'
# Initializing an empty DataFrame with specified column names
prs_result = pd.DataFrame(columns=["clump_p1", "clump_r2", "clump_kb", "p_window_size", "p_slide_size", "p_LD_threshold",
"pvalue", "model","numberofpca","h2","lambda","numberofvariants(m)","Train_pure_prs", "Train_null_model", "Train_best_model",
"Test_pure_prs","ldscmodel" ,"Test_null_model", "Test_best_model"])
Define Helper Functions#
Perform Clumping and Pruning
Calculate PCA Using Plink
Fit Binary Phenotype and Save Results
Fit Continuous Phenotype and Save Results
import os
import subprocess
import pandas as pd
import statsmodels.api as sm
from sklearn.metrics import explained_variance_score
def perform_clumping_and_pruning_on_individual_data(traindirec, newtrainfilename,numberofpca, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile):
command = [
"./plink",
"--bfile", traindirec+os.sep+newtrainfilename,
"--indep-pairwise", p1_val, p2_val, p3_val,
"--out", traindirec+os.sep+trainfilename
]
subprocess.call(command)
# First perform pruning and then clumping and the pruning.
command = [
"./plink",
"--bfile", traindirec+os.sep+newtrainfilename,
"--clump-p1", c1_val,
"--extract", traindirec+os.sep+trainfilename+".prune.in",
"--clump-r2", c2_val,
"--clump-kb", c3_val,
"--clump", filedirec+os.sep+filedirec+".txt",
"--clump-snp-field", "SNP",
"--clump-field", "P",
"--out", traindirec+os.sep+trainfilename
]
subprocess.call(command)
# Extract the valid SNPs from th clumped file.
# For windows download gwak for linux awk commmand is sufficient.
### For windows require GWAK.
### https://sourceforge.net/projects/gnuwin32/
##3 Get it and place it in the same direc.
#os.system("gawk "+"\""+"NR!=1{print $3}"+"\" "+ traindirec+os.sep+trainfilename+".clumped > "+traindirec+os.sep+trainfilename+".valid.snp")
#print("gawk "+"\""+"NR!=1{print $3}"+"\" "+ traindirec+os.sep+trainfilename+".clumped > "+traindirec+os.sep+trainfilename+".valid.snp")
#Linux:
command = "awk 'NR!=1{{print $3}}' {}{}{}.clumped > {}{}{}.valid.snp".format(
traindirec, os.sep, trainfilename,
traindirec, os.sep, trainfilename
)
os.system(command)
command = [
"./plink",
"--make-bed",
"--bfile", traindirec+os.sep+newtrainfilename,
"--indep-pairwise", p1_val, p2_val, p3_val,
"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--out", traindirec+os.sep+newtrainfilename+".clumped.pruned"
]
subprocess.call(command)
command = [
"./plink",
"--make-bed",
"--bfile", traindirec+os.sep+testfilename,
"--indep-pairwise", p1_val, p2_val, p3_val,
"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--out", traindirec+os.sep+testfilename+".clumped.pruned"
]
subprocess.call(command)
def calculate_pca_for_traindata_testdata_for_clumped_pruned_snps(traindirec, newtrainfilename,p):
# Calculate the PRS for the test data using the same set of SNPs and also calculate the PCA.
# Also extract the PCA at this point.
# PCA are calculated afer clumping and pruining.
command = [
"./plink",
"--bfile", folddirec+os.sep+testfilename+".clumped.pruned",
# Select the final variants after clumping and pruning.
"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--pca", p,
"--out", folddirec+os.sep+testfilename
]
subprocess.call(command)
command = [
"./plink",
"--bfile", traindirec+os.sep+newtrainfilename+".clumped.pruned",
# Select the final variants after clumping and pruning.
"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--pca", p,
"--out", traindirec+os.sep+trainfilename
]
subprocess.call(command)
# This function fit the binary model on the PRS.
def fit_binary_phenotype_on_PRS(traindirec, newtrainfilename,hapmapmodel,ldpredbin ,p, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile,h2):
threshold_values = allpvalues
# Merge the covariates, pca and phenotypes.
tempphenotype_train = pd.read_table(traindirec+os.sep+newtrainfilename+".clumped.pruned"+".fam", sep="\s+",header=None)
phenotype_train = pd.DataFrame()
phenotype_train["Phenotype"] = tempphenotype_train[5].values
pcs_train = pd.read_table(traindirec+os.sep+trainfilename+".eigenvec", sep="\s+",header=None, names=["FID", "IID"] + ["PC{}".format(str(i)) for i in range(1, int(p) + 1)])
covariate_train = pd.read_table(traindirec+os.sep+trainfilename+".cov",sep="\s+")
covariate_train.fillna(0, inplace=True)
covariate_train = covariate_train[covariate_train["FID"].isin(pcs_train["FID"].values) & covariate_train["IID"].isin(pcs_train["IID"].values)]
covariate_train['FID'] = covariate_train['FID'].astype(str)
pcs_train['FID'] = pcs_train['FID'].astype(str)
covariate_train['IID'] = covariate_train['IID'].astype(str)
pcs_train['IID'] = pcs_train['IID'].astype(str)
covandpcs_train = pd.merge(covariate_train, pcs_train, on=["FID","IID"])
covandpcs_train.fillna(0, inplace=True)
## Scale the covariates!
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import explained_variance_score
scaler = MinMaxScaler()
normalized_values_train = scaler.fit_transform(covandpcs_train.iloc[:, 2:])
#covandpcs_train.iloc[:, 2:] = normalized_values_test
tempphenotype_test = pd.read_table(traindirec+os.sep+testfilename+".clumped.pruned"+".fam", sep="\s+",header=None)
phenotype_test= pd.DataFrame()
phenotype_test["Phenotype"] = tempphenotype_test[5].values
pcs_test = pd.read_table(traindirec+os.sep+testfilename+".eigenvec", sep="\s+",header=None, names=["FID", "IID"] + ["PC{}".format(str(i)) for i in range(1, int(p) + 1)])
covariate_test = pd.read_table(traindirec+os.sep+testfilename+".cov",sep="\s+")
covariate_test.fillna(0, inplace=True)
covariate_test = covariate_test[covariate_test["FID"].isin(pcs_test["FID"].values) & covariate_test["IID"].isin(pcs_test["IID"].values)]
covariate_test['FID'] = covariate_test['FID'].astype(str)
pcs_test['FID'] = pcs_test['FID'].astype(str)
covariate_test['IID'] = covariate_test['IID'].astype(str)
pcs_test['IID'] = pcs_test['IID'].astype(str)
covandpcs_test = pd.merge(covariate_test, pcs_test, on=["FID","IID"])
covandpcs_test.fillna(0, inplace=True)
normalized_values_test = scaler.transform(covandpcs_test.iloc[:, 2:])
#covandpcs_test.iloc[:, 2:] = normalized_values_test
tempalphas = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
l1weights = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
tempalphas = [0.1]
l1weights = [0.1]
phenotype_train["Phenotype"] = phenotype_train["Phenotype"].replace({1: 0, 2: 1})
phenotype_test["Phenotype"] = phenotype_test["Phenotype"].replace({1: 0, 2: 1})
for tempalpha in tempalphas:
for l1weight in l1weights:
try:
null_model = sm.Logit(phenotype_train["Phenotype"], sm.add_constant(covandpcs_train.iloc[:, 2:])).fit_regularized(alpha=tempalpha, L1_wt=l1weight)
#null_model = sm.Logit(phenotype_train["Phenotype"], sm.add_constant(covandpcs_train.iloc[:, 2:])).fit()
except:
print("XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX")
continue
train_null_predicted = null_model.predict(sm.add_constant(covandpcs_train.iloc[:, 2:]))
from sklearn.metrics import roc_auc_score, confusion_matrix
from sklearn.metrics import r2_score
test_null_predicted = null_model.predict(sm.add_constant(covandpcs_test.iloc[:, 2:]))
global prs_result
for i in threshold_values:
try:
prs_train = pd.read_table(
traindirec + os.sep + Name + os.sep + "train_data.pv_{}.profile".format(i),
sep="\s+",
usecols=["FID", "IID", "SCORE"]
)
except:
continue
prs_train['FID'] = prs_train['FID'].astype(str)
prs_train['IID'] = prs_train['IID'].astype(str)
try:
prs_test = pd.read_table(
traindirec + os.sep + Name + os.sep + "test_data.pv_{}.profile".format(i),
sep="\s+",
usecols=["FID", "IID", "SCORE"]
)
except:
continue
prs_test['FID'] = prs_test['FID'].astype(str)
prs_test['IID'] = prs_test['IID'].astype(str)
pheno_prs_train = pd.merge(covandpcs_train, prs_train, on=["FID", "IID"])
pheno_prs_test = pd.merge(covandpcs_test, prs_test, on=["FID", "IID"])
try:
model = sm.Logit(phenotype_train["Phenotype"], sm.add_constant(pheno_prs_train.iloc[:, 2:])).fit_regularized(alpha=tempalpha, L1_wt=l1weight)
#model = sm.Logit(phenotype_train["Phenotype"], sm.add_constant(pheno_prs_train.iloc[:, 2:])).fit()
except:
continue
train_best_predicted = model.predict(sm.add_constant(pheno_prs_train.iloc[:, 2:]))
test_best_predicted = model.predict(sm.add_constant(pheno_prs_test.iloc[:, 2:]))
from sklearn.metrics import roc_auc_score, confusion_matrix
prs_result = prs_result.append({
"clump_p1": c1_val,
"clump_r2": c2_val,
"clump_kb": c3_val,
"p_window_size": p1_val,
"p_slide_size": p2_val,
"p_LD_threshold": p3_val,
"pvalue": i,
"numberofpca":p,
"tempalpha":str(tempalpha),
"l1weight":str(l1weight),
"numberofvariants": len(pd.read_csv(traindirec+os.sep+newtrainfilename+".clumped.pruned.bim")),
"h2model":hapmapmodel,
"h2":h2,
"LDpred-funct-bins":ldpredbin,
"Train_pure_prs":roc_auc_score(phenotype_train["Phenotype"].values,prs_train['SCORE'].values),
"Train_null_model":roc_auc_score(phenotype_train["Phenotype"].values,train_null_predicted.values),
"Train_best_model":roc_auc_score(phenotype_train["Phenotype"].values,train_best_predicted.values),
"Test_pure_prs":roc_auc_score(phenotype_test["Phenotype"].values,prs_test['SCORE'].values),
"Test_null_model":roc_auc_score(phenotype_test["Phenotype"].values,test_null_predicted.values),
"Test_best_model":roc_auc_score(phenotype_test["Phenotype"].values,test_best_predicted.values),
}, ignore_index=True)
prs_result.to_csv(traindirec+os.sep+Name+os.sep+"Results.csv",index=False)
return
# This function fit the binary model on the PRS.
def fit_continous_phenotype_on_PRS(traindirec, newtrainfilename,hapmapmodel,ldpredbin ,p, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile,h2):
threshold_values = allpvalues
# Merge the covariates, pca and phenotypes.
tempphenotype_train = pd.read_table(traindirec+os.sep+newtrainfilename+".clumped.pruned"+".fam", sep="\s+",header=None)
phenotype_train = pd.DataFrame()
phenotype_train["Phenotype"] = tempphenotype_train[5].values
pcs_train = pd.read_table(traindirec+os.sep+trainfilename+".eigenvec", sep="\s+",header=None, names=["FID", "IID"] + ["PC{}".format(str(i)) for i in range(1, int(p) + 1)])
covariate_train = pd.read_table(traindirec+os.sep+trainfilename+".cov",sep="\s+")
covariate_train.fillna(0, inplace=True)
covariate_train = covariate_train[covariate_train["FID"].isin(pcs_train["FID"].values) & covariate_train["IID"].isin(pcs_train["IID"].values)]
covariate_train['FID'] = covariate_train['FID'].astype(str)
pcs_train['FID'] = pcs_train['FID'].astype(str)
covariate_train['IID'] = covariate_train['IID'].astype(str)
pcs_train['IID'] = pcs_train['IID'].astype(str)
covandpcs_train = pd.merge(covariate_train, pcs_train, on=["FID","IID"])
covandpcs_train.fillna(0, inplace=True)
## Scale the covariates!
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import explained_variance_score
scaler = MinMaxScaler()
normalized_values_train = scaler.fit_transform(covandpcs_train.iloc[:, 2:])
#covandpcs_train.iloc[:, 2:] = normalized_values_test
tempphenotype_test = pd.read_table(traindirec+os.sep+testfilename+".clumped.pruned"+".fam", sep="\s+",header=None)
phenotype_test= pd.DataFrame()
phenotype_test["Phenotype"] = tempphenotype_test[5].values
pcs_test = pd.read_table(traindirec+os.sep+testfilename+".eigenvec", sep="\s+",header=None, names=["FID", "IID"] + ["PC{}".format(str(i)) for i in range(1, int(p) + 1)])
covariate_test = pd.read_table(traindirec+os.sep+testfilename+".cov",sep="\s+")
covariate_test.fillna(0, inplace=True)
covariate_test = covariate_test[covariate_test["FID"].isin(pcs_test["FID"].values) & covariate_test["IID"].isin(pcs_test["IID"].values)]
covariate_test['FID'] = covariate_test['FID'].astype(str)
pcs_test['FID'] = pcs_test['FID'].astype(str)
covariate_test['IID'] = covariate_test['IID'].astype(str)
pcs_test['IID'] = pcs_test['IID'].astype(str)
covandpcs_test = pd.merge(covariate_test, pcs_test, on=["FID","IID"])
covandpcs_test.fillna(0, inplace=True)
normalized_values_test = scaler.transform(covandpcs_test.iloc[:, 2:])
#covandpcs_test.iloc[:, 2:] = normalized_values_test
tempalphas = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
l1weights = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
tempalphas = [0.1]
l1weights = [0.1]
#phenotype_train["Phenotype"] = phenotype_train["Phenotype"].replace({1: 0, 2: 1})
#phenotype_test["Phenotype"] = phenotype_test["Phenotype"].replace({1: 0, 2: 1})
for tempalpha in tempalphas:
for l1weight in l1weights:
try:
#null_model = sm.OLS(phenotype_train["Phenotype"], sm.add_constant(covandpcs_train.iloc[:, 2:])).fit_regularized(alpha=tempalpha, L1_wt=l1weight)
null_model = sm.OLS(phenotype_train["Phenotype"], sm.add_constant(covandpcs_train.iloc[:, 2:])).fit()
#null_model = sm.OLS(phenotype_train["Phenotype"], sm.add_constant(covandpcs_train.iloc[:, 2:])).fit()
except:
print("XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX")
continue
train_null_predicted = null_model.predict(sm.add_constant(covandpcs_train.iloc[:, 2:]))
from sklearn.metrics import roc_auc_score, confusion_matrix
from sklearn.metrics import r2_score
test_null_predicted = null_model.predict(sm.add_constant(covandpcs_test.iloc[:, 2:]))
global prs_result
for i in threshold_values:
try:
prs_train = pd.read_table(
traindirec + os.sep + Name + os.sep + "train_data.pv_{}.profile".format(i),
sep="\s+",
usecols=["FID", "IID", "SCORE"]
)
except:
continue
prs_train['FID'] = prs_train['FID'].astype(str)
prs_train['IID'] = prs_train['IID'].astype(str)
try:
prs_test = pd.read_table(
traindirec + os.sep + Name + os.sep + "test_data.pv_{}.profile".format(i),
sep="\s+",
usecols=["FID", "IID", "SCORE"]
)
except:
continue
prs_test['FID'] = prs_test['FID'].astype(str)
prs_test['IID'] = prs_test['IID'].astype(str)
pheno_prs_train = pd.merge(covandpcs_train, prs_train, on=["FID", "IID"])
pheno_prs_test = pd.merge(covandpcs_test, prs_test, on=["FID", "IID"])
try:
#model = sm.OLS(phenotype_train["Phenotype"], sm.add_constant(pheno_prs_train.iloc[:, 2:])).fit_regularized(alpha=tempalpha, L1_wt=l1weight)
model = sm.OLS(phenotype_train["Phenotype"], sm.add_constant(pheno_prs_train.iloc[:, 2:])).fit()
except:
continue
train_best_predicted = model.predict(sm.add_constant(pheno_prs_train.iloc[:, 2:]))
test_best_predicted = model.predict(sm.add_constant(pheno_prs_test.iloc[:, 2:]))
from sklearn.metrics import roc_auc_score, confusion_matrix
prs_result = prs_result.append({
"clump_p1": c1_val,
"clump_r2": c2_val,
"clump_kb": c3_val,
"p_window_size": p1_val,
"p_slide_size": p2_val,
"p_LD_threshold": p3_val,
"pvalue": i,
"numberofpca":p,
"numberofvariants": len(pd.read_csv(traindirec+os.sep+newtrainfilename+".clumped.pruned.bim")),
"h2model":hapmapmodel,
"h2":h2,
"LDpred-funct-bins":ldpredbin,
"Train_pure_prs":explained_variance_score(phenotype_train["Phenotype"],prs_train['SCORE'].values),
"Train_null_model":explained_variance_score(phenotype_train["Phenotype"],train_null_predicted),
"Train_best_model":explained_variance_score(phenotype_train["Phenotype"],train_best_predicted),
"Test_pure_prs":explained_variance_score(phenotype_test["Phenotype"],prs_test['SCORE'].values),
"Test_null_model":explained_variance_score(phenotype_test["Phenotype"],test_null_predicted),
"Test_best_model":explained_variance_score(phenotype_test["Phenotype"],test_best_predicted),
}, ignore_index=True)
prs_result.to_csv(traindirec+os.sep+Name+os.sep+"Results.csv",index=False)
return
Execute LDpred-funct#
def transform_ldpred_funct_data(traindirec, newtrainfilename,hapmapmodel,ldpredbin,p, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile):
### First perform clumping on the file and save the clumpled file.
#perform_clumping_and_pruning_on_individual_data(traindirec, newtrainfilename,p, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile)
# Also extract the PCA at this point for both test and training data.
#calculate_pca_for_traindata_testdata_for_clumped_pruned_snps(traindirec, newtrainfilename,p)
#Extract p-values from the GWAS file.
#os.system("awk "+"\'"+"{print $3,$8}"+"\'"+" ./"+filedirec+os.sep+filedirec+".txt > ./"+traindirec+os.sep+"SNP.pvalue")
# At this stage, we will merge the PCA and COV file.
tempphenotype_train = pd.read_table(traindirec+os.sep+newtrainfilename+".clumped.pruned"+".fam", sep="\s+",header=None)
phenotype = pd.DataFrame()
phenotype = tempphenotype_train[[0,1,5]]
phenotype.to_csv(traindirec+os.sep+trainfilename+".PHENO",sep="\t",header=['FID', 'IID', 'PHENO'],index=False)
pcs_train = pd.read_table(
os.path.join(traindirec, trainfilename + ".eigenvec"),
sep="\s+",
header=None,
names=["FID", "IID"] + ["PC" + str(i) for i in range(1, int(p) + 1)]
)
covariate_train = pd.read_table(traindirec+os.sep+trainfilename+".cov",sep="\s+")
covariate_train.fillna(0, inplace=True)
covariate_train.to_csv(traindirec+os.sep+trainfilename+".cov",sep="\t",index=False)
covariate_train = pd.read_table(traindirec+os.sep+trainfilename+".cov",sep="\s+")
covariate_train = covariate_train[covariate_train["FID"].isin(pcs_train["FID"].values) & covariate_train["IID"].isin(pcs_train["IID"].values)]
covariate_train['FID'] = covariate_train['FID'].astype(str)
pcs_train['FID'] = pcs_train['FID'].astype(str)
covariate_train['IID'] = covariate_train['IID'].astype(str)
pcs_train['IID'] = pcs_train['IID'].astype(str)
covandpcs_train = pd.merge(covariate_train, pcs_train, on=["FID","IID"])
covandpcs_train.to_csv(traindirec+os.sep+trainfilename+".COV_PCA",sep="\t",index=False)
# Define the paths to the files to be removed.
files_to_remove = [
traindirec+os.sep+"LDPRED_baseline.results",
traindirec+os.sep+"LDPRED_baseline.log",
traindirec+os.sep+"ldpredfunct_posterior_means",
traindirec+os.sep+"ldpredfunct_posterior_means_LDpred-inf-ldscore.txt",
traindirec+os.sep+"functfile.txt",
traindirec+os.sep+"ldpredfunct_gwas.txt",
traindirec+os.sep+"functfile.txt",
]
# Loop through the files and remove them if they exist
for file_path in files_to_remove:
if os.path.exists(file_path):
os.remove(file_path)
print("Removed: {}".format(file_path))
else:
print("File does not exist: {}".format(file_path))
if os.path.exists(traindirec+os.sep+"Coord_Final"):
# Delete the file
os.remove(traindirec+os.sep+"Coord_Final")
ldpath = "LDSCFILES/"
if hapmapmodel =="full":
command = [
"python",
"ldsc/munge_sumstats.py",
"--sumstats", filedirec+os.sep+"LDpred_funct_LDSC.txt",
#"--merge-alleles", ldpath+os.sep+"w_hm3.snplist",
"--out", filedirec+os.sep+"LDPRED",
"--a1-inc"
]
subprocess.call(command)
if hapmapmodel =="hapmap":
command = [
"python",
"ldsc/munge_sumstats.py",
"--sumstats", filedirec+os.sep+"LDpred_funct_LDSC.txt",
"--merge-alleles", ldpath+os.sep+"w_hm3.snplist.bz2",
"--out", filedirec+os.sep+"LDPRED",
"--a1-inc"
]
subprocess.call(command)
print(" ".join(command))
command = [
"python", "ldsc/ldsc.py",
"--h2", filedirec+os.sep+"LDPRED"+".sumstats.gz",
"--ref-ld-chr", ldpath+os.sep+"baseline/baselineLD.@",
#"--ref-ld-chr", ldpath+os.sep+"celltype/cell_type_group.1.@",
"--w-ld-chr", ldpath+os.sep+"weights/weights.@",
"--overlap-annot",
"--print-coefficients",
"--frqfile-chr", ldpath+os.sep+"freq/1000G.EUR.QC.",
"--out", traindirec+os.sep+"LDPRED_baseline",
]
# Run the command
print(" ".join(command))
subprocess.call(command)
#raise
h2 = ""
def makefunctfile():
import re
with open(traindirec+os.sep+"LDPRED_baseline.log", 'r') as file:
lines = file.readlines()
matching_lines = [line.strip() for line in lines if re.search(r'Total Observed scale h2:', line)]
for line in matching_lines:
h2 = float(line.split(":")[1].split(" ")[1])
print(line.split(":")[1].split(" ")[1])
result = pd.read_csv(traindirec+os.sep+"LDPRED_baseline.results",sep="\t")
result["Coefficient"] = result["Coefficient"]/h2
h2frame = result[["Coefficient"]]
print(h2frame.head())
#print(len(result))
import gzip
result_list = []
snp_list = []
for loop in range(1,23):
with gzip.open(ldpath+os.sep+"baseline/baselineLD."+str(loop)+".annot.gz", 'rt') as file:
tempdf = pd.read_csv(file, sep='\t', comment='#')
##with gzip.open(ldpath+os.sep+"celltype/cell_type_group.1."+str(loop)+".annot.gz", 'rt') as file:
# tempdf = pd.read_csv(file, sep='\t', comment='#')
# Print headers
#print("Original Headers:")
#print(tempdf.columns)
# Remove the first four columns
snp_list.extend(tempdf["SNP"].values)
tempdf = tempdf.iloc[:, 4:]
#print(len(tempdf.columns))
result = np.dot(tempdf.values,h2frame.values).flatten()
result_list.extend(result)
print(result)
#final_result = np.concatenate(result_list, axis=1)
# Create a DataFrame from the final result
result_df = pd.DataFrame()
result_df["V2"] = snp_list
result_df["h2snp"] = result_list
#result_df = pd.DataFrame(result_list, columns=['Dot_Product_Result'])
result_df.to_csv(traindirec+os.sep+"functfile.txt",sep="\t",index=False)
#print(result_df)
# The calculation for the funct file required by LDpred-funct is specified on their GitHub account.
makefunctfile()
plinkfile = traindirec+os.sep+newtrainfilename+".clumped.pruned.[1:22]"
functfile = traindirec+os.sep+"functfile.txt"
outCoord = traindirec+os.sep+"Coord_Final"
statsfile = filedirec+os.sep+"_LDpred_funct.txt"
N = len(pd.read_csv(traindirec+os.sep+newtrainfilename+".clumped.pruned"+".fam",sep="\t"))
outLdpredfunct =traindirec+os.sep+"ldpredfunct_posterior_means"
import re
with open(traindirec+os.sep+"LDPRED_baseline.log", 'r') as file:
lines = file.readlines()
matching_lines = [line.strip() for line in lines if re.search(r'Total Observed scale h2:', line)]
for line in matching_lines:
h2 = float(line.split(":")[1].split(" ")[1])
h2 = h2
outValidate = traindirec+os.sep+"ldpredfunct_prs"
tempphenotype_train = pd.read_table(traindirec+os.sep+newtrainfilename+".clumped.pruned"+".fam", sep="\s+",header=None)
phenotype = pd.DataFrame()
phenotype = tempphenotype_train[[0,5]]
phenotype.to_csv(traindirec+os.sep+trainfilename+".ldpred_funct_pheno",sep="\t",index=False,header=None)
phenotype = traindirec+os.sep+trainfilename+".ldpred_funct_pheno"
# Construct the command
for chromosome in range(1,23):
plink_command = [
"./plink",
"--bfile", traindirec+os.sep+newtrainfilename+".clumped.pruned",
"--chr", str(chromosome),
"--make-bed",
"--out", traindirec+os.sep+newtrainfilename+".clumped.pruned."+str(chromosome)
]
subprocess.call(plink_command)
command = [
"python",
"LDpred-funct/ldpredfunct.py",
"--gf=" + plinkfile,
"--pf=" + phenotype,
"--FUNCT_FILE=" + functfile,
"--coord=" + outCoord,
"--ssf=" + statsfile,
"--N=" + str(N),
"--posterior_means=" + outLdpredfunct,
"--H2=" + str(h2),
"--out=" + outValidate,
"--K="+str(ldpredbin),
]
try:
subprocess.call(command)
print(" ".join(command))
except:
print("LDpred-funct did not work! kindly see the logs generated. May be the isssue is the limited number of variants.")
pass
#exit(0)
#raise
temp = pd.read_csv(traindirec+os.sep+"ldpredfunct_posterior_means_LDpred-inf-ldscore.txt",sep="\s+" )
if check_phenotype_is_binary_or_continous(filedirec)=="Binary":
temp["ldpred_inf_beta"] = np.exp(temp["ldpred_inf_beta"])
else:
pass
temp = temp.rename(columns={"sid": "SNP", "nt1": "A1", "ldpred_inf_beta": "BETA"})
temp[["SNP","A1","BETA"]].to_csv(traindirec+os.sep+"ldpredfunct_gwas.txt",sep="\t",index=False)
command = [
"./plink",
"--bfile", traindirec+os.sep+newtrainfilename,
### SNP column = 3, Effect allele column 1 = 4, OR column=7
"--score", traindirec+os.sep+"ldpredfunct_gwas.txt", "1", "2", "3", "header",
"--q-score-range", traindirec+os.sep+"range_list",traindirec+os.sep+"SNP.pvalue",
#"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--out", traindirec+os.sep+Name+os.sep+trainfilename
]
#exit(0)
subprocess.call(command)
#raise
# Calculate the PRS for the test data using the same set of SNPs and also calculate the PCA.
command = [
"./plink",
"--bfile", folddirec+os.sep+testfilename,
### SNP column = 3, Effect allele column 1 = 4, OR column=7
"--score", traindirec+os.sep+"ldpredfunct_gwas.txt", "1", "2", "3", "header",
"--q-score-range", traindirec+os.sep+"range_list",traindirec+os.sep+"SNP.pvalue",
#"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--out", folddirec+os.sep+Name+os.sep+testfilename
]
subprocess.call(command)
if check_phenotype_is_binary_or_continous(filedirec)=="Binary":
print("Binary Phenotype!")
fit_binary_phenotype_on_PRS(traindirec, newtrainfilename,hapmapmodel,ldpredbin ,p, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile,h2)
else:
print("Continous Phenotype!")
fit_continous_phenotype_on_PRS(traindirec, newtrainfilename,hapmapmodel,ldpredbin ,p, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile,h2)
hapmapmodels = ["hapmap","full"]
hapmapmodels = ["full"]
ldpredbins = ["2","10"]
ldpredbins = ["2"]
result_directory = "LDpred-funct"
# Nested loops to iterate over different parameter values
create_directory(folddirec+os.sep+"LDpred-funct")
for p1_val in p_window_size:
for p2_val in p_slide_size:
for p3_val in p_LD_threshold:
for c1_val in clump_p1:
for c2_val in clump_r2:
for c3_val in clump_kb:
for p in numberofpca:
for hapmapmodel in hapmapmodels:
for ldpredbin in ldpredbins:
#ldscmodel = "X"
transform_ldpred_funct_data(folddirec, newtrainfilename,hapmapmodel,ldpredbin ,p, str(p1_val), str(p2_val), str(p3_val), str(c1_val), str(c2_val), str(c3_val), "LDpred-funct", pvaluefile)
/data/ascher01/uqmmune1/miniconda3/envs/ldscc/lib/python2.7/site-packages/ipykernel_launcher.py:16: FutureWarning: read_table is deprecated, use read_csv instead.
app.launch_new_instance()
/data/ascher01/uqmmune1/miniconda3/envs/ldscc/lib/python2.7/site-packages/ipykernel_launcher.py:25: FutureWarning: read_table is deprecated, use read_csv instead.
/data/ascher01/uqmmune1/miniconda3/envs/ldscc/lib/python2.7/site-packages/ipykernel_launcher.py:27: FutureWarning: read_table is deprecated, use read_csv instead.
/data/ascher01/uqmmune1/miniconda3/envs/ldscc/lib/python2.7/site-packages/ipykernel_launcher.py:30: FutureWarning: read_table is deprecated, use read_csv instead.
Removed: SampleData1/Fold_0/LDPRED_baseline.results
Removed: SampleData1/Fold_0/LDPRED_baseline.log
File does not exist: SampleData1/Fold_0/ldpredfunct_posterior_means
Removed: SampleData1/Fold_0/ldpredfunct_posterior_means_LDpred-inf-ldscore.txt
Removed: SampleData1/Fold_0/functfile.txt
Removed: SampleData1/Fold_0/ldpredfunct_gwas.txt
File does not exist: SampleData1/Fold_0/functfile.txt
python ldsc/munge_sumstats.py --sumstats SampleData1/LDpred_funct_LDSC.txt --out SampleData1/LDPRED --a1-inc
python ldsc/ldsc.py --h2 SampleData1/LDPRED.sumstats.gz --ref-ld-chr LDSCFILES//baseline/baselineLD.@ --w-ld-chr LDSCFILES//weights/weights.@ --overlap-annot --print-coefficients --frqfile-chr LDSCFILES//freq/1000G.EUR.QC. --out SampleData1/Fold_0/LDPRED_baseline
0.6332
Coefficient
0 4.709126e-08
1 1.044727e-07
2 1.262486e-08
3 -3.604682e-08
4 2.760955e-08
[-2.10761886e-07 -2.10758415e-07 1.02259746e-07 ... 6.07420819e-08
-1.94921600e-07 2.69159041e-07]
[ 1.15568116e-07 2.44089650e-07 1.39739329e-07 ... 6.96371216e-08
-2.11952456e-07 -4.04429933e-07]
[ 6.89768759e-08 1.07186730e-07 3.21524271e-07 ... 3.53575274e-07
-3.25233011e-08 1.29297052e-07]
[ 2.71325795e-07 1.40518687e-07 -3.03163985e-08 ... 1.20070971e-08
-1.89865404e-07 -5.33779357e-08]
[ 2.00482258e-07 2.39700575e-08 2.39786526e-08 ... -4.68520689e-08
-8.93657984e-08 -2.65981772e-07]
[ 1.99410502e-07 1.99637973e-07 -7.14928762e-08 ... -3.24849857e-08
-1.73179095e-07 -1.73190494e-07]
[3.19445903e-08 1.38136875e-07 1.56328690e-08 ... 5.94348819e-07
6.84326633e-07 2.17017534e-07]
[ 3.04248004e-07 2.51932123e-07 2.57428180e-07 ... -9.26107073e-08
8.32429429e-09 1.46922795e-07]
[-1.81127615e-07 -1.81126794e-07 1.41420020e-07 ... -2.90032420e-08
9.78240003e-07 2.45797638e-07]
[-4.09061268e-08 -3.27997646e-08 -3.27981979e-08 ... 2.85124777e-10
3.28018040e-07 7.94158512e-08]
[ 2.06584865e-08 -3.65449335e-07 -3.25014980e-08 ... 4.94668350e-07
2.04988708e-07 6.28657853e-08]
[-1.75116448e-07 -4.62829500e-08 6.81949847e-08 ... 6.34503321e-08
6.34448170e-08 6.34434321e-08]
[ 1.97688547e-08 1.65883710e-07 1.62691283e-07 ... -5.90888250e-08
4.72690485e-07 1.70102352e-07]
[ 3.51638905e-09 1.74557699e-07 1.74589617e-07 ... 3.55143500e-07
-8.33843440e-08 3.13413727e-07]
[ 2.28657853e-07 2.28686060e-07 3.91325854e-07 ... -2.15282129e-08
-3.75470703e-07 -8.42692614e-09]
[-1.69261791e-07 -1.72397920e-07 -5.09106208e-07 ... -1.49170508e-07
1.93003126e-07 -1.55136797e-07]
[ 2.46001068e-07 2.36944305e-07 2.86892933e-07 ... -5.69183236e-08
-1.38467659e-07 -2.30404381e-07]
[ 1.26305159e-07 -5.73051614e-07 -5.41194747e-07 ... -5.03809810e-08
1.64736119e-07 -1.22203410e-07]
[-7.03266722e-08 -1.30371044e-07 -1.18913162e-07 ... -2.42348024e-07
4.16125231e-07 7.00194146e-07]
[ 3.60512169e-07 4.07831787e-08 5.03794240e-07 ... -2.21502237e-07
1.58710087e-07 -9.80753002e-08]
[-8.29189152e-08 -1.10700521e-08 1.26948027e-07 ... -6.99187696e-08
2.09043208e-07 1.86898306e-07]
[ 9.34712086e-08 1.85966281e-07 7.37557830e-08 ... -1.79490453e-07
-2.84459944e-08 -2.51229265e-08]
/data/ascher01/uqmmune1/miniconda3/envs/ldscc/lib/python2.7/site-packages/ipykernel_launcher.py:195: FutureWarning: read_table is deprecated, use read_csv instead.
python LDpred-funct/ldpredfunct.py --gf=SampleData1/Fold_0/train_data.QC.clumped.pruned.[1:22] --pf=SampleData1/Fold_0/train_data.ldpred_funct_pheno --FUNCT_FILE=SampleData1/Fold_0/functfile.txt --coord=SampleData1/Fold_0/Coord_Final --ssf=SampleData1/_LDpred_funct.txt --N=379 --posterior_means=SampleData1/Fold_0/ldpredfunct_posterior_means --H2=0.6332 --out=SampleData1/Fold_0/ldpredfunct_prs --K=2
Continous Phenotype!
/data/ascher01/uqmmune1/miniconda3/envs/ldscc/lib/python2.7/site-packages/ipykernel_launcher.py:257: FutureWarning: read_table is deprecated, use read_csv instead.
/data/ascher01/uqmmune1/miniconda3/envs/ldscc/lib/python2.7/site-packages/ipykernel_launcher.py:260: FutureWarning: read_table is deprecated, use read_csv instead.
/data/ascher01/uqmmune1/miniconda3/envs/ldscc/lib/python2.7/site-packages/ipykernel_launcher.py:261: FutureWarning: read_table is deprecated, use read_csv instead.
/data/ascher01/uqmmune1/miniconda3/envs/ldscc/lib/python2.7/site-packages/ipykernel_launcher.py:279: FutureWarning: read_table is deprecated, use read_csv instead.
/data/ascher01/uqmmune1/miniconda3/envs/ldscc/lib/python2.7/site-packages/ipykernel_launcher.py:282: FutureWarning: read_table is deprecated, use read_csv instead.
/data/ascher01/uqmmune1/miniconda3/envs/ldscc/lib/python2.7/site-packages/ipykernel_launcher.py:283: FutureWarning: read_table is deprecated, use read_csv instead.
/data/ascher01/uqmmune1/miniconda3/envs/ldscc/lib/python2.7/site-packages/ipykernel_launcher.py:334: FutureWarning: read_table is deprecated, use read_csv instead.
/data/ascher01/uqmmune1/miniconda3/envs/ldscc/lib/python2.7/site-packages/ipykernel_launcher.py:345: FutureWarning: read_table is deprecated, use read_csv instead.
Repeat the process for each fold.#
Change the foldnumber variable.
#foldnumber = sys.argv[1]
foldnumber = "0" # Setting 'foldnumber' to "0"
Or uncomment the following line:
# foldnumber = sys.argv[1]
python LDpred-funct-code.py 0
python LDpred-funct-code.py 1
python LDpred-funct-code.py 2
python LDpred-funct-code.py 3
python LDpred-funct-code.py 4
The following files should exist after the execution:
SampleData1/Fold_0/LDpred-funct/Results.csvSampleData1/Fold_1/LDpred-funct/Results.csvSampleData1/Fold_2/LDpred-funct/Results.csvSampleData1/Fold_3/LDpred-funct/Results.csvSampleData1/Fold_4/LDpred-funct/Results.csv
Check the results file for each fold.#
import os
import pandas as pd
filedirec = "SampleData1"
result_directory = "LDpred-funct"
# List of file names to check for existence
f = [
"./"+filedirec+"/Fold_0"+os.sep+result_directory+"Results.csv",
"./"+filedirec+"/Fold_1"+os.sep+result_directory+"Results.csv",
"./"+filedirec+"/Fold_2"+os.sep+result_directory+"Results.csv",
"./"+filedirec+"/Fold_3"+os.sep+result_directory+"Results.csv",
"./"+filedirec+"/Fold_4"+os.sep+result_directory+"Results.csv",
]
# Loop through each file name in the list
for loop in range(0,5):
# Check if the file exists in the specified directory for the given fold
if os.path.exists(filedirec+os.sep+"Fold_"+str(loop)+os.sep+result_directory+os.sep+"Results.csv"):
temp = pd.read_csv(filedirec+os.sep+"Fold_"+str(loop)+os.sep+result_directory+os.sep+"Results.csv")
print("Fold_",loop, "Yes, the file exists.")
#print(temp.head())
print("Number of P-values processed: ",len(temp))
# Print a message indicating that the file exists
else:
# Print a message indicating that the file does not exist
print("Fold_",loop, "No, the file does not exist.")
('Fold_', 0, 'Yes, the file exists.')
('Number of P-values processed: ', 20)
('Fold_', 1, 'Yes, the file exists.')
('Number of P-values processed: ', 20)
('Fold_', 2, 'Yes, the file exists.')
('Number of P-values processed: ', 20)
('Fold_', 3, 'Yes, the file exists.')
('Number of P-values processed: ', 20)
('Fold_', 4, 'Yes, the file exists.')
('Number of P-values processed: ', 20)
Sum the results for each fold.#
print("We have to ensure when we sum the entries across all Folds, the same rows are merged!")
def sum_and_average_columns(data_frames):
"""Sum and average numerical columns across multiple DataFrames, and keep non-numerical columns unchanged."""
# Initialize DataFrame to store the summed results for numerical columns
summed_df = pd.DataFrame()
non_numerical_df = pd.DataFrame()
for df in data_frames:
# Identify numerical and non-numerical columns
numerical_cols = df.select_dtypes(include=[np.number]).columns
non_numerical_cols = df.select_dtypes(exclude=[np.number]).columns
# Sum numerical columns
if summed_df.empty:
summed_df = pd.DataFrame(0, index=range(len(df)), columns=numerical_cols)
summed_df[numerical_cols] = summed_df[numerical_cols].add(df[numerical_cols], fill_value=0)
# Keep non-numerical columns (take the first non-numerical entry for each column)
if non_numerical_df.empty:
non_numerical_df = df[non_numerical_cols]
else:
non_numerical_df[non_numerical_cols] = non_numerical_df[non_numerical_cols].combine_first(df[non_numerical_cols])
# Divide the summed values by the number of dataframes to get the average
averaged_df = summed_df / len(data_frames)
# Combine numerical and non-numerical DataFrames
result_df = pd.concat([averaged_df, non_numerical_df], axis=1)
return result_df
from functools import reduce
import numpy as np
import os
import pandas as pd
from functools import reduce
def dataframe_to_markdown(df):
# Create the header
header = "| " + " | ".join(df.columns) + " |"
separator = "| " + " | ".join(['---'] * len(df.columns)) + " |"
# Create the rows
rows = []
for index, row in df.iterrows():
row_string = "| " + " | ".join([str(item) for item in row]) + " |"
rows.append(row_string)
# Combine all parts into the final markdown string
markdown = header + "\n" + separator + "\n" + "\n".join(rows)
return markdown
def find_common_rows(allfoldsframe):
# Define the performance columns that need to be excluded
performance_columns = [
'Train_null_model', 'Train_pure_prs', 'Train_best_model',
'Test_pure_prs', 'Test_null_model', 'Test_best_model'
]
important_columns = [
'clump_p1',
'clump_r2',
'clump_kb',
'p_window_size',
'p_slide_size',
'p_LD_threshold',
'pvalue',
'referencepanel',
'PRSice-2_Model',
'effectsizes',
'h2model',
#'lambda',
#'delta',
'model',
'numberofpca',
'tempalpha',
'l1weight',
'LDpred-funct-bins',
"heritability_model",
"unique_h2",
"grid_pvalue",
"burn_in",
"num_iter",
"sparse",
"temp_pvalue",
"allow_jump_sign" ,
"shrink_corr" ,
"use_MLE" ,
#"sparsity",
"lasso_parameters_count",
]
# Function to remove performance columns from a DataFrame
def drop_performance_columns(df):
return df.drop(columns=performance_columns, errors='ignore')
def get_important_columns(df ):
existing_columns = [col for col in important_columns if col in df.columns]
if existing_columns:
return df[existing_columns].copy()
else:
return pd.DataFrame()
# Drop performance columns from all DataFrames in the list
allfoldsframe_dropped = [drop_performance_columns(df) for df in allfoldsframe]
# Get the important columns.
allfoldsframe_dropped = [get_important_columns(df) for df in allfoldsframe_dropped]
common_rows = allfoldsframe_dropped[0]
print(dataframe_to_markdown(common_rows.head()))
for i in range(1, len(allfoldsframe_dropped)):
# Get the next DataFrame
next_df = allfoldsframe_dropped[i]
# Count unique rows in the current DataFrame and the next DataFrame
unique_in_common = common_rows.shape[0]
unique_in_next = next_df.shape[0]
# Find common rows between the current common_rows and the next DataFrame
common_rows = pd.merge(common_rows, next_df, how='inner')
# Count the common rows after merging
common_count = common_rows.shape[0]
print(dataframe_to_markdown(common_rows.head()))
# Print the unique and common row counts
print("Iteration {}:".format(i))
print("Unique rows in current common DataFrame: {}".format(unique_in_common))
print("Unique rows in next DataFrame: {}".format(unique_in_next))
print("Common rows after merge: {}\n".format(common_count))
# Now that we have the common rows, extract these from the original DataFrames
extracted_common_rows_frames = []
for original_df in allfoldsframe:
# Merge the common rows with the original DataFrame, keeping only the rows that match the common rows
extracted_common_rows = pd.merge(common_rows, original_df, how='inner', on=common_rows.columns.tolist())
# Add the DataFrame with the extracted common rows to the list
extracted_common_rows_frames.append(extracted_common_rows)
# Print the number of rows in the common DataFrames
for i, df in enumerate(extracted_common_rows_frames):
print("DataFrame {} with extracted common rows has {} rows.".format(i + 1, df.shape[0]))
# Return the list of DataFrames with extracted common rows
return extracted_common_rows_frames
# Example usage (assuming allfoldsframe is populated as shown earlier):
allfoldsframe = []
# Loop through each file name in the list
for loop in range(0, 5):
# Check if the file exists in the specified directory for the given fold
file_path = os.path.join(filedirec, "Fold_" + str(loop), result_directory, "Results.csv")
if os.path.exists(file_path):
allfoldsframe.append(pd.read_csv(file_path))
# Print a message indicating that the file exists
print("Fold_", loop, "Yes, the file exists.")
else:
# Print a message indicating that the file does not exist
print("Fold_", loop, "No, the file does not exist.")
# Find the common rows across all folds and return the list of extracted common rows
extracted_common_rows_list = find_common_rows(allfoldsframe)
# Sum the values column-wise
# For string values, do not sum it the values are going to be the same for each fold.
# Only sum the numeric values.
divided_result = sum_and_average_columns(extracted_common_rows_list)
print(divided_result)
We have to ensure when we sum the entries across all Folds, the same rows are merged!
('Fold_', 0, 'Yes, the file exists.')
('Fold_', 1, 'Yes, the file exists.')
('Fold_', 2, 'Yes, the file exists.')
('Fold_', 3, 'Yes, the file exists.')
('Fold_', 4, 'Yes, the file exists.')
| clump_p1 | clump_r2 | clump_kb | p_window_size | p_slide_size | p_LD_threshold | pvalue | h2model | model | numberofpca | LDpred-funct-bins |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 1e-10 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 3.35981828628e-10 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 1.12883789168e-09 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 3.79269019073e-09 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 1.2742749857e-08 | full | nan | 6 | 2 |
| clump_p1 | clump_r2 | clump_kb | p_window_size | p_slide_size | p_LD_threshold | pvalue | h2model | model | numberofpca | LDpred-funct-bins |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 1e-10 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 3.35981828628e-10 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 1.12883789168e-09 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 3.79269019073e-09 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 1.2742749857e-08 | full | nan | 6 | 2 |
Iteration 1:
Unique rows in current common DataFrame: 20
Unique rows in next DataFrame: 20
Common rows after merge: 20
| clump_p1 | clump_r2 | clump_kb | p_window_size | p_slide_size | p_LD_threshold | pvalue | h2model | model | numberofpca | LDpred-funct-bins |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 1e-10 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 3.35981828628e-10 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 1.12883789168e-09 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 3.79269019073e-09 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 1.2742749857e-08 | full | nan | 6 | 2 |
Iteration 2:
Unique rows in current common DataFrame: 20
Unique rows in next DataFrame: 20
Common rows after merge: 20
| clump_p1 | clump_r2 | clump_kb | p_window_size | p_slide_size | p_LD_threshold | pvalue | h2model | model | numberofpca | LDpred-funct-bins |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 1e-10 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 3.35981828628e-10 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 1.12883789168e-09 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 3.79269019073e-09 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 1.2742749857e-08 | full | nan | 6 | 2 |
Iteration 3:
Unique rows in current common DataFrame: 20
Unique rows in next DataFrame: 20
Common rows after merge: 20
| clump_p1 | clump_r2 | clump_kb | p_window_size | p_slide_size | p_LD_threshold | pvalue | h2model | model | numberofpca | LDpred-funct-bins |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 1e-10 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 3.35981828628e-10 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 1.12883789168e-09 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 3.79269019073e-09 | full | nan | 6 | 2 |
| 1 | 0.1 | 200 | 200 | 50 | 0.25 | 1.2742749857e-08 | full | nan | 6 | 2 |
Iteration 4:
Unique rows in current common DataFrame: 20
Unique rows in next DataFrame: 20
Common rows after merge: 20
DataFrame 1 with extracted common rows has 20 rows.
DataFrame 2 with extracted common rows has 20 rows.
DataFrame 3 with extracted common rows has 20 rows.
DataFrame 4 with extracted common rows has 20 rows.
DataFrame 5 with extracted common rows has 20 rows.
clump_p1 clump_r2 clump_kb p_window_size p_slide_size p_LD_threshold \
0 1.0 0.1 200.0 200.0 50.0 0.25
1 1.0 0.1 200.0 200.0 50.0 0.25
2 1.0 0.1 200.0 200.0 50.0 0.25
3 1.0 0.1 200.0 200.0 50.0 0.25
4 1.0 0.1 200.0 200.0 50.0 0.25
5 1.0 0.1 200.0 200.0 50.0 0.25
6 1.0 0.1 200.0 200.0 50.0 0.25
7 1.0 0.1 200.0 200.0 50.0 0.25
8 1.0 0.1 200.0 200.0 50.0 0.25
9 1.0 0.1 200.0 200.0 50.0 0.25
10 1.0 0.1 200.0 200.0 50.0 0.25
11 1.0 0.1 200.0 200.0 50.0 0.25
12 1.0 0.1 200.0 200.0 50.0 0.25
13 1.0 0.1 200.0 200.0 50.0 0.25
14 1.0 0.1 200.0 200.0 50.0 0.25
15 1.0 0.1 200.0 200.0 50.0 0.25
16 1.0 0.1 200.0 200.0 50.0 0.25
17 1.0 0.1 200.0 200.0 50.0 0.25
18 1.0 0.1 200.0 200.0 50.0 0.25
19 1.0 0.1 200.0 200.0 50.0 0.25
pvalue model numberofpca LDpred-funct-bins ... \
0 1.000000e-10 0.0 6.0 2.0 ...
1 3.359818e-10 0.0 6.0 2.0 ...
2 1.128838e-09 0.0 6.0 2.0 ...
3 3.792690e-09 0.0 6.0 2.0 ...
4 1.274275e-08 0.0 6.0 2.0 ...
5 4.281332e-08 0.0 6.0 2.0 ...
6 1.438450e-07 0.0 6.0 2.0 ...
7 4.832930e-07 0.0 6.0 2.0 ...
8 1.623777e-06 0.0 6.0 2.0 ...
9 5.455595e-06 0.0 6.0 2.0 ...
10 1.832981e-05 0.0 6.0 2.0 ...
11 6.158482e-05 0.0 6.0 2.0 ...
12 2.069138e-04 0.0 6.0 2.0 ...
13 6.951928e-04 0.0 6.0 2.0 ...
14 2.335721e-03 0.0 6.0 2.0 ...
15 7.847600e-03 0.0 6.0 2.0 ...
16 2.636651e-02 0.0 6.0 2.0 ...
17 8.858668e-02 0.0 6.0 2.0 ...
18 2.976351e-01 0.0 6.0 2.0 ...
19 1.000000e+00 0.0 6.0 2.0 ...
numberofvariants(m) Train_pure_prs Train_null_model Train_best_model \
0 0.0 6.764905e-06 0.23001 0.234406
1 0.0 5.658587e-06 0.23001 0.233978
2 0.0 5.762025e-06 0.23001 0.235546
3 0.0 6.119490e-06 0.23001 0.237609
4 0.0 6.702985e-06 0.23001 0.242886
5 0.0 5.625974e-06 0.23001 0.243031
6 0.0 5.405208e-06 0.23001 0.245582
7 0.0 4.122190e-06 0.23001 0.244376
8 0.0 4.028646e-06 0.23001 0.248732
9 0.0 4.100213e-06 0.23001 0.256975
10 0.0 3.950130e-06 0.23001 0.267563
11 0.0 3.449541e-06 0.23001 0.274810
12 0.0 2.927592e-06 0.23001 0.279277
13 0.0 2.647879e-06 0.23001 0.290300
14 0.0 2.189178e-06 0.23001 0.301650
15 0.0 1.787224e-06 0.23001 0.308934
16 0.0 1.247514e-06 0.23001 0.313359
17 0.0 8.776203e-07 0.23001 0.316582
18 0.0 6.109545e-07 0.23001 0.328056
19 0.0 3.650838e-07 0.23001 0.331060
Test_pure_prs ldscmodel Test_null_model Test_best_model \
0 3.711239e-06 0.0 0.118692 0.117637
1 2.903363e-06 0.0 0.118692 0.113459
2 3.919729e-06 0.0 0.118692 0.118935
3 4.784125e-06 0.0 0.118692 0.121026
4 5.409369e-06 0.0 0.118692 0.128612
5 4.641353e-06 0.0 0.118692 0.130670
6 5.030032e-06 0.0 0.118692 0.132575
7 4.120422e-06 0.0 0.118692 0.131295
8 3.926443e-06 0.0 0.118692 0.132846
9 4.035996e-06 0.0 0.118692 0.141315
10 3.912030e-06 0.0 0.118692 0.157448
11 3.496461e-06 0.0 0.118692 0.175260
12 3.040849e-06 0.0 0.118692 0.174844
13 2.771833e-06 0.0 0.118692 0.195946
14 2.269089e-06 0.0 0.118692 0.213451
15 1.834660e-06 0.0 0.118692 0.225897
16 1.281239e-06 0.0 0.118692 0.234362
17 9.074813e-07 0.0 0.118692 0.246118
18 6.299871e-07 0.0 0.118692 0.262952
19 3.786930e-07 0.0 0.118692 0.261404
numberofvariants h2model
0 173107.8 full
1 173107.8 full
2 173107.8 full
3 173107.8 full
4 173107.8 full
5 173107.8 full
6 173107.8 full
7 173107.8 full
8 173107.8 full
9 173107.8 full
10 173107.8 full
11 173107.8 full
12 173107.8 full
13 173107.8 full
14 173107.8 full
15 173107.8 full
16 173107.8 full
17 173107.8 full
18 173107.8 full
19 173107.8 full
[20 rows x 22 columns]
Results#
1. Reporting Based on Best Training Performance:#
One can report the results based on the best performance of the training data. For example, if for a specific combination of hyperparameters, the training performance is high, report the corresponding test performance.
Example code:
df = divided_result.sort_values(by='Train_best_model', ascending=False) print(df.iloc[0].to_markdown())
Binary Phenotypes Result Analysis#
You can find the performance quality for binary phenotype using the following template:
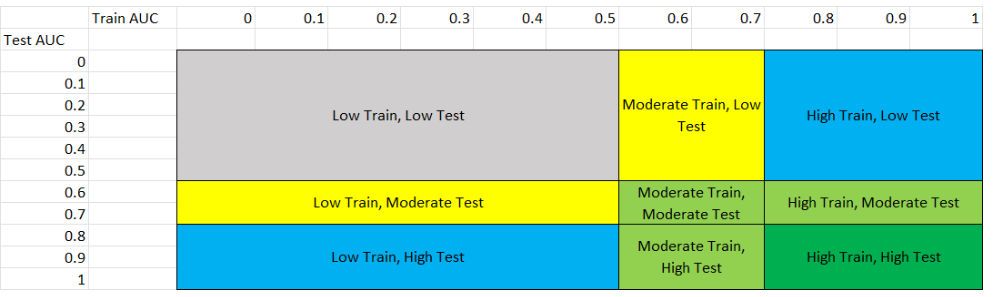
This figure shows the 8 different scenarios that can exist in the results, and the following table explains each scenario.
We classified performance based on the following table:
Performance Level |
Range |
|---|---|
Low Performance |
0 to 0.5 |
Moderate Performance |
0.6 to 0.7 |
High Performance |
0.8 to 1 |
You can match the performance based on the following scenarios:
Scenario |
What’s Happening |
Implication |
|---|---|---|
High Test, High Train |
The model performs well on both training and test datasets, effectively learning the underlying patterns. |
The model is well-tuned, generalizes well, and makes accurate predictions on both datasets. |
High Test, Moderate Train |
The model generalizes well but may not be fully optimized on training data, missing some underlying patterns. |
The model is fairly robust but may benefit from further tuning or more training to improve its learning. |
High Test, Low Train |
An unusual scenario, potentially indicating data leakage or overestimation of test performance. |
The model’s performance is likely unreliable; investigate potential data issues or random noise. |
Moderate Test, High Train |
The model fits the training data well but doesn’t generalize as effectively, capturing only some test patterns. |
The model is slightly overfitting; adjustments may be needed to improve generalization on unseen data. |
Moderate Test, Moderate Train |
The model shows balanced but moderate performance on both datasets, capturing some patterns but missing others. |
The model is moderately fitting; further improvements could be made in both training and generalization. |
Moderate Test, Low Train |
The model underperforms on training data and doesn’t generalize well, leading to moderate test performance. |
The model may need more complexity, additional features, or better training to improve on both datasets. |
Low Test, High Train |
The model overfits the training data, performing poorly on the test set. |
The model doesn’t generalize well; simplifying the model or using regularization may help reduce overfitting. |
Low Test, Low Train |
The model performs poorly on both training and test datasets, failing to learn the data patterns effectively. |
The model is underfitting; it may need more complexity, additional features, or more data to improve performance. |
Recommendations for Publishing Results#
When publishing results, scenarios with moderate train and moderate test performance can be used for complex phenotypes or diseases. However, results showing high train and moderate test, high train and high test, and moderate train and high test are recommended.
For most phenotypes, results typically fall in the moderate train and moderate test performance category.
Continuous Phenotypes Result Analysis#
You can find the performance quality for continuous phenotypes using the following template:
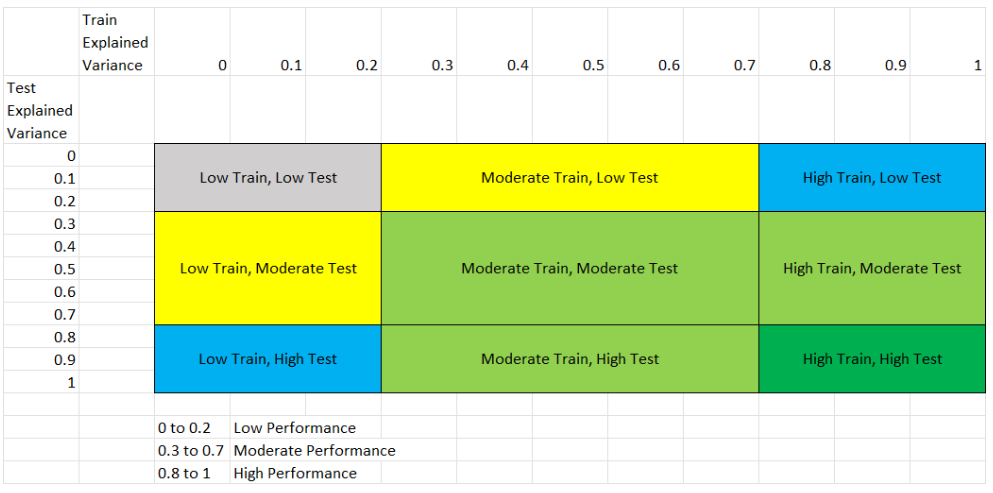
This figure shows the 8 different scenarios that can exist in the results, and the following table explains each scenario.
We classified performance based on the following table:
Performance Level |
Range |
|---|---|
Low Performance |
0 to 0.2 |
Moderate Performance |
0.3 to 0.7 |
High Performance |
0.8 to 1 |
You can match the performance based on the following scenarios:
Scenario |
What’s Happening |
Implication |
|---|---|---|
High Test, High Train |
The model performs well on both training and test datasets, effectively learning the underlying patterns. |
The model is well-tuned, generalizes well, and makes accurate predictions on both datasets. |
High Test, Moderate Train |
The model generalizes well but may not be fully optimized on training data, missing some underlying patterns. |
The model is fairly robust but may benefit from further tuning or more training to improve its learning. |
High Test, Low Train |
An unusual scenario, potentially indicating data leakage or overestimation of test performance. |
The model’s performance is likely unreliable; investigate potential data issues or random noise. |
Moderate Test, High Train |
The model fits the training data well but doesn’t generalize as effectively, capturing only some test patterns. |
The model is slightly overfitting; adjustments may be needed to improve generalization on unseen data. |
Moderate Test, Moderate Train |
The model shows balanced but moderate performance on both datasets, capturing some patterns but missing others. |
The model is moderately fitting; further improvements could be made in both training and generalization. |
Moderate Test, Low Train |
The model underperforms on training data and doesn’t generalize well, leading to moderate test performance. |
The model may need more complexity, additional features, or better training to improve on both datasets. |
Low Test, High Train |
The model overfits the training data, performing poorly on the test set. |
The model doesn’t generalize well; simplifying the model or using regularization may help reduce overfitting. |
Low Test, Low Train |
The model performs poorly on both training and test datasets, failing to learn the data patterns effectively. |
The model is underfitting; it may need more complexity, additional features, or more data to improve performance. |
Recommendations for Publishing Results#
When publishing results, scenarios with moderate train and moderate test performance can be used for complex phenotypes or diseases. However, results showing high train and moderate test, high train and high test, and moderate train and high test are recommended.
For most continuous phenotypes, results typically fall in the moderate train and moderate test performance category.
2. Reporting Generalized Performance:#
One can also report the generalized performance by calculating the difference between the training and test performance, and the sum of the test and training performance. Report the result or hyperparameter combination for which the sum is high and the difference is minimal.
Example code:
df = divided_result.copy() df['Difference'] = abs(df['Train_best_model'] - df['Test_best_model']) df['Sum'] = df['Train_best_model'] + df['Test_best_model'] sorted_df = df.sort_values(by=['Sum', 'Difference'], ascending=[False, True]) print(sorted_df.iloc[0].to_markdown())
3. Reporting Hyperparameters Affecting Test and Train Performance:#
Find the hyperparameters that have more than one unique value and calculate their correlation with the following columns to understand how they are affecting the performance of train and test sets:
Train_null_modelTrain_pure_prsTrain_best_modelTest_pure_prsTest_null_modelTest_best_model
4. Other Analysis#
Once you have the results, you can find how hyperparameters affect the model performance.
Analysis, like overfitting and underfitting, can be performed as well.
The way you are going to report the results can vary.
Results can be visualized, and other patterns in the data can be explored.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib notebook
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
# In Python 2, use 'plt.ion()' to enable interactive mode
plt.ion()
df = divided_result.sort_values(by='Train_best_model', ascending=False)
print("1. Reporting Based on Best Training Performance:\n")
print(df.iloc[0])
df = divided_result.copy()
# Plot Train and Test best models against p-values
plt.figure(figsize=(10, 6))
plt.plot(df['pvalue'], df['Train_best_model'], label='Train_best_model', marker='o', color='royalblue')
plt.plot(df['pvalue'], df['Test_best_model'], label='Test_best_model', marker='o', color='darkorange')
# Highlight the p-value where both train and test are high
best_index = df[['Train_best_model']].sum(axis=1).idxmax()
best_pvalue = df.loc[best_index, 'pvalue']
best_train = df.loc[best_index, 'Train_best_model']
best_test = df.loc[best_index, 'Test_best_model']
# Use dark colors for the circles
plt.scatter(best_pvalue, best_train, color='darkred', s=100, label='Best Performance (Train)', edgecolor='black', zorder=5)
plt.scatter(best_pvalue, best_test, color='darkblue', s=100, label='Best Performance (Test)', edgecolor='black', zorder=5)
# Annotate the best performance with p-value, train, and test values
plt.text(best_pvalue, best_train, 'p=%0.4g\nTrain=%0.4g' % (best_pvalue, best_train), ha='right', va='bottom', fontsize=9, color='darkred')
plt.text(best_pvalue, best_test, 'p=%0.4g\nTest=%0.4g' % (best_pvalue, best_test), ha='right', va='top', fontsize=9, color='darkblue')
# Calculate Difference and Sum
df['Difference'] = abs(df['Train_best_model'] - df['Test_best_model'])
df['Sum'] = df['Train_best_model'] + df['Test_best_model']
# Sort the DataFrame
sorted_df = df.sort_values(by=['Sum', 'Difference'], ascending=[False, True])
# Highlight the general performance
general_index = sorted_df.index[0]
general_pvalue = sorted_df.loc[general_index, 'pvalue']
general_train = sorted_df.loc[general_index, 'Train_best_model']
general_test = sorted_df.loc[general_index, 'Test_best_model']
plt.scatter(general_pvalue, general_train, color='darkgreen', s=150, label='General Performance (Train)', edgecolor='black', zorder=6)
plt.scatter(general_pvalue, general_test, color='darkorange', s=150, label='General Performance (Test)', edgecolor='black', zorder=6)
# Annotate the general performance with p-value, train, and test values
plt.text(general_pvalue, general_train, 'p=%0.4g\nTrain=%0.4g' % (general_pvalue, general_train), ha='right', va='bottom', fontsize=9, color='darkgreen')
plt.text(general_pvalue, general_test, 'p=%0.4g\nTest=%0.4g' % (general_pvalue, general_test), ha='right', va='top', fontsize=9, color='darkorange')
# Add labels and legend
plt.xlabel('p-value')
plt.ylabel('Model Performance')
plt.title('Train vs Test Best Models')
plt.legend()
plt.show()
print("2. Reporting Generalized Performance:\n")
df = divided_result.copy()
df['Difference'] = abs(df['Train_best_model'] - df['Test_best_model'])
df['Sum'] = df['Train_best_model'] + df['Test_best_model']
sorted_df = df.sort_values(by=['Sum', 'Difference'], ascending=[False, True])
print(sorted_df.iloc[0])
print("3. Reporting the correlation of hyperparameters and the performance of 'Train_null_model', 'Train_pure_prs', 'Train_best_model', 'Test_pure_prs', 'Test_null_model', and 'Test_best_model':\n")
print("3. For string hyperparameters, we used one-hot encoding to find the correlation between string hyperparameters and 'Train_null_model', 'Train_pure_prs', 'Train_best_model', 'Test_pure_prs', 'Test_null_model', and 'Test_best_model'.")
print("3. We performed this analysis for those hyperparameters that have more than one unique value.")
correlation_columns = [
'Train_null_model', 'Train_pure_prs', 'Train_best_model',
'Test_pure_prs', 'Test_null_model', 'Test_best_model'
]
hyperparams = [col for col in divided_result.columns if len(divided_result[col].unique()) > 1]
hyperparams = list(set(hyperparams + correlation_columns))
# Separate numeric and string columns
numeric_hyperparams = [col for col in hyperparams if pd.api.types.is_numeric_dtype(divided_result[col])]
string_hyperparams = [col for col in hyperparams if pd.api.types.is_string_dtype(divided_result[col])]
# Encode string columns using one-hot encoding
divided_result_encoded = pd.get_dummies(divided_result, columns=string_hyperparams)
# Combine numeric hyperparams with the new one-hot encoded columns
encoded_columns = [col for col in divided_result_encoded.columns if col.startswith(tuple(string_hyperparams))]
hyperparams = numeric_hyperparams + encoded_columns
# Calculate correlations
correlations = divided_result_encoded[hyperparams].corr()
# Display correlation of hyperparameters with train/test performance columns
hyperparam_correlations = correlations.loc[hyperparams, correlation_columns]
hyperparam_correlations = hyperparam_correlations.fillna(0)
# Plotting the correlation heatmap
plt.figure(figsize=(12, 8))
ax = sns.heatmap(hyperparam_correlations, annot=True, cmap='viridis', fmt='.2f', cbar=True)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90, ha='right')
# Rotate y-axis labels to horizontal
#ax.set_yticklabels(ax.get_yticklabels(), rotation=0, va='center')
plt.title('Correlation of Hyperparameters with Train/Test Performance')
plt.show()
sns.set_style("whitegrid") # Choose your preferred style
pairplot = sns.pairplot(divided_result_encoded[hyperparams], hue='Test_best_model', palette='viridis')
# Adjust the figure size
pairplot.fig.set_size_inches(15, 15) # You can adjust the size as needed
for ax in pairplot.axes.flatten():
ax.set_xlabel(ax.get_xlabel(), rotation=90, ha='right') # X-axis labels vertical
#ax.set_ylabel(ax.get_ylabel(), rotation=0, va='bottom') # Y-axis labels horizontal
# Show the plot
plt.show()
1. Reporting Based on Best Training Performance:
clump_p1 1
clump_r2 0.1
clump_kb 200
p_window_size 200
p_slide_size 50
p_LD_threshold 0.25
pvalue 1
model 0
numberofpca 6
LDpred-funct-bins 2
h2 0.6332
lambda 0
numberofvariants(m) 0
Train_pure_prs 3.65084e-07
Train_null_model 0.23001
Train_best_model 0.33106
Test_pure_prs 3.78693e-07
ldscmodel 0
Test_null_model 0.118692
Test_best_model 0.261404
numberofvariants 173108
h2model full
Name: 19, dtype: object

2. Reporting Generalized Performance:
clump_p1 1
clump_r2 0.1
clump_kb 200
p_window_size 200
p_slide_size 50
p_LD_threshold 0.25
pvalue 1
model 0
numberofpca 6
LDpred-funct-bins 2
h2 0.6332
lambda 0
numberofvariants(m) 0
Train_pure_prs 3.65084e-07
Train_null_model 0.23001
Train_best_model 0.33106
Test_pure_prs 3.78693e-07
ldscmodel 0
Test_null_model 0.118692
Test_best_model 0.261404
numberofvariants 173108
h2model full
Difference 0.0696555
Sum 0.592464
Name: 19, dtype: object
3. Reporting the correlation of hyperparameters and the performance of 'Train_null_model', 'Train_pure_prs', 'Train_best_model', 'Test_pure_prs', 'Test_null_model', and 'Test_best_model':
3. For string hyperparameters, we used one-hot encoding to find the correlation between string hyperparameters and 'Train_null_model', 'Train_pure_prs', 'Train_best_model', 'Test_pure_prs', 'Test_null_model', and 'Test_best_model'.
3. We performed this analysis for those hyperparameters that have more than one unique value.

