PRSbils#
In this notebook, we will use PRSbils (Polygenic risk score with bilevel continuous shrinkage for incorporating functional annotations.) to calculate the PRS.
PRSbils uses LD reference panel for calculation: PRSbils GitHub.
Download PRSbils#
One can download the PRScs using the following command:
git clone https://github.com/styvon/PRSbils.git
PRSbils: Polygenic Risk Score with Bilevel Continuous Shrinkage#
Usage:
PRSbils.py [-h] --ref_dir REF_DIR --bim_prefix BIM_PREFIX --sst_file SST_FILE --map_file MAP_FILE [--map_gcol MAP_GCOL] --n_gwas N_GWAS --out_dir OUT_DIR [--a A] [--b B] [--c C] [--d D] [--e E] [--f F] [--n_iter N_ITER] [--chrom CHROM [CHROM ...]] [--beta_std [BETA_STD]] [--thres THRES] [--ignore_blk [IGNORE_BLK]] [--verbose [VERBOSE]] [--fixtau [FIXTAU]] [--flip [FLIP]]
Here is the command line tool usage in a vertical format, represented in Markdown:
PRSbils.py
[-h]
--ref_dir REF_DIR
--bim_prefix BIM_PREFIX
--sst_file SST_FILE
--map_file MAP_FILE
[--map_gcol MAP_GCOL]
--n_gwas N_GWAS
--out_dir OUT_DIR
[--a A]
[--b B]
[--c C]
[--d D]
[--e E]
[--f F]
[--n_iter N_ITER]
[--chrom CHROM [CHROM ...]]
[--beta_std [BETA_STD]]
[--thres THRES]
[--ignore_blk [IGNORE_BLK]]
[--verbose [VERBOSE]]
[--fixtau [FIXTAU]]
[--flip [FLIP]]
Arguments:
Argument |
Description |
Default |
|---|---|---|
|
Full path to directory containing LD reference panel (snpinfo_1kg_hm3 and ldblk_1kg_chr*.hdf5) |
- |
|
Full path and prefix of the bim file |
- |
|
Full path and name of GWAS summary statistics file |
- |
|
Full path and name of the SNP to sets mapping file |
- |
|
Column id for group info in map_file (not yet implemented) |
None |
|
Sample size of the GWAS |
- |
|
Output directory and filename prefix for the posterior effect size estimates |
- |
|
Parameter a for sigma |
0.001 |
|
Parameter b in the gamma prior for sigma |
0.001 |
|
Parameter c for group implementation |
0.001 |
|
Parameter d for group implementation |
0.001 |
|
Parameter e for lambda |
1 |
|
Parameter f for lambda |
0.5 |
|
Number of maximum iterations |
1000 |
|
The chromosome on which the model is fitted |
Iterating through 22 autosomes |
|
Boolean. If True, return standardized posterior SNP effect sizes |
False |
|
Threshold value for convergence |
0.001 |
|
Boolean. If false, elements categorized as same set but in different ld will be treated as different sets |
False |
|
Boolean |
False |
|
Boolean. If false, will estimate tau in algorithm, otherwise will fix at 1 |
False |
|
Boolean. If false, signs of beta in summary statistics will not be flipped when there’s a switch in A1 and A2 alleles |
False |
The process of calculating PRS is simple.
Here you can download the reference panels used by PRScs and information is taken from the PRScs GitHub: PRScs GitHub.
LD Reference Panels#
1000 Genomes Project Phase 3 Samples#
Population |
Download Link |
Size |
Extraction Command |
|---|---|---|---|
AFR |
~4.44G |
|
|
AMR |
~3.84G |
|
|
EAS |
~4.33G |
|
|
EUR |
~4.56G |
|
|
SAS |
~5.60G |
|
UK Biobank Data (Notes)#
Population |
Download Link |
Size |
Extraction Command |
|---|---|---|---|
AFR |
~4.93G |
|
|
AMR |
~4.10G |
|
|
EAS |
~5.80G |
|
|
EUR |
~6.25G |
|
|
SAS |
~7.37G |
|
For regions that don’t have access to Dropbox, reference panels can be downloaded from the alternative download site.
GWAS File Processing for PRSbils#
When the effect size relates to disease risk and is thus given as an odds ratio (OR) rather than BETA (for continuous traits), the PRS is computed as a product of ORs. To simplify this calculation, take the natural logarithm of the OR so that the PRS can be computed using summation instead.
Example Data:#
Using BETA:
SNP |
A1 |
A2 |
BETA |
SE |
|---|---|---|---|---|
rs4970383 |
C |
A |
-0.0064 |
0.0090 |
rs4475691 |
C |
T |
-0.0145 |
0.0094 |
rs13302982 |
A |
G |
-0.0232 |
0.0199 |
Using OR:
SNP |
A1 |
A2 |
OR |
SE |
|---|---|---|---|---|
rs4970383 |
A |
C |
0.9825 |
0.0314 |
rs4475691 |
T |
C |
0.9436 |
0.0319 |
rs13302982 |
A |
G |
1.1337 |
0.0543 |
import os
import pandas as pd
import numpy as np
#filedirec = sys.argv[1]
filedirec = "SampleData1"
#filedirec = "asthma_19"
#filedirec = "migraine_0"
def check_phenotype_is_binary_or_continous(filedirec):
# Read the processed quality controlled file for a phenotype
df = pd.read_csv(filedirec+os.sep+filedirec+'_QC.fam',sep="\s+",header=None)
column_values = df[5].unique()
if len(set(column_values)) == 2:
return "Binary"
else:
return "Continous"
# Read the GWAS file.
GWAS = filedirec + os.sep + filedirec+".gz"
df = pd.read_csv(GWAS,compression= "gzip",sep="\s+")
def check_phenotype_is_binary_or_continous(filedirec):
# Read the processed quality controlled file for a phenotype
df = pd.read_csv(filedirec+os.sep+filedirec+'_QC.fam',sep="\s+",header=None)
column_values = df[5].unique()
if len(set(column_values)) == 2:
return "Binary"
else:
return "Continous"
if check_phenotype_is_binary_or_continous(filedirec)=="Binary":
if "BETA" in df.columns.to_list():
# For Binary Phenotypes.
df["OR"] = np.exp(df["BETA"])
df = df[['CHR', 'BP', 'SNP', 'A1', 'A2', 'N', 'SE', 'P', 'OR', 'INFO', 'MAF']]
else:
# For Binary Phenotype.
df = df[['CHR', 'BP', 'SNP', 'A1', 'A2', 'N', 'SE', 'P', 'OR', 'INFO', 'MAF']]
df.to_csv(filedirec + os.sep +filedirec+".txt",sep="\t",index=False)
df_transformed = pd.DataFrame({
'SNP': df['SNP'],
'A1': df['A1'],
'A2': df['A2'],
'OR': df['OR'],
'P': df['P'],
})
elif check_phenotype_is_binary_or_continous(filedirec)=="Continous":
if "BETA" in df.columns.to_list():
# For Continous Phenotype.
df = df[['CHR', 'BP', 'SNP', 'A1', 'A2', 'N', 'SE', 'P', 'BETA', 'INFO', 'MAF']]
else:
df["BETA"] = np.log(df["OR"])
df = df[['CHR', 'BP', 'SNP', 'A1', 'A2', 'N', 'SE', 'P', 'BETA', 'INFO', 'MAF']]
df.to_csv(filedirec + os.sep +filedirec+".txt",sep="\t",index=False)
df_transformed = pd.DataFrame({
'SNP': df['SNP'],
'A1': df['A1'],
'A2': df['A2'],
'BETA': df['BETA'],
'P': df['P'],
})
n_gwas = df["N"].mean()
df_transformed.to_csv(filedirec + os.sep +filedirec+".PRSbils",sep="\t",index=False)
print(df_transformed.head().to_markdown())
print("Length of DataFrame!",len(df_transformed))
| | SNP | A1 | A2 | BETA | P |
|---:|:-----------|:-----|:-----|------------:|---------:|
| 0 | rs3131962 | A | G | -0.00211532 | 0.483171 |
| 1 | rs12562034 | A | G | 0.00068708 | 0.834808 |
| 2 | rs4040617 | G | A | -0.00239932 | 0.42897 |
| 3 | rs79373928 | G | T | 0.00203363 | 0.808999 |
| 4 | rs11240779 | G | A | 0.00130747 | 0.590265 |
Length of DataFrame! 499617
Define Hyperparameters#
Define hyperparameters to be optimized and set initial values.
Extract Valid SNPs from Clumped File#
For Windows, download gwak, and for Linux, the awk command is sufficient. For Windows, GWAK is required. You can download it from here. Get it and place it in the same directory.
Execution Path#
At this stage, we have the genotype training data newtrainfilename = "train_data.QC" and genotype test data newtestfilename = "test_data.QC".
We modified the following variables:
filedirec = "SampleData1"orfiledirec = sys.argv[1]foldnumber = "0"orfoldnumber = sys.argv[2]for HPC.
Only these two variables can be modified to execute the code for specific data and specific folds. Though the code can be executed separately for each fold on HPC and separately for each dataset, it is recommended to execute it for multiple diseases and one fold at a time. Here’s the corrected text in Markdown format:
P-values#
PRS calculation relies on P-values. SNPs with low P-values, indicating a high degree of association with a specific trait, are considered for calculation.
You can modify the code below to consider a specific set of P-values and save the file in the same format.
We considered the following parameters:
Minimum P-value:
1e-10Maximum P-value:
1.0Minimum exponent:
10(Minimum P-value in exponent)Number of intervals:
100(Number of intervals to be considered)
The code generates an array of logarithmically spaced P-values:
import numpy as np
import os
minimumpvalue = 10 # Minimum exponent for P-values
numberofintervals = 100 # Number of intervals to be considered
allpvalues = np.logspace(-minimumpvalue, 0, numberofintervals, endpoint=True) # Generating an array of logarithmically spaced P-values
print("Minimum P-value:", allpvalues[0])
print("Maximum P-value:", allpvalues[-1])
count = 1
with open(os.path.join(folddirec, 'range_list'), 'w') as file:
for value in allpvalues:
file.write(f'pv_{value} 0 {value}\n') # Writing range information to the 'range_list' file
count += 1
pvaluefile = os.path.join(folddirec, 'range_list')
In this code:
minimumpvaluedefines the minimum exponent for P-values.numberofintervalsspecifies how many intervals to consider.allpvaluesgenerates an array of P-values spaced logarithmically.The script writes these P-values to a file named
range_listin the specified directory.
from operator import index
import pandas as pd
import numpy as np
import os
import subprocess
import sys
import pandas as pd
import statsmodels.api as sm
import pandas as pd
from sklearn.metrics import roc_auc_score, confusion_matrix
from statsmodels.stats.contingency_tables import mcnemar
def create_directory(directory):
"""Function to create a directory if it doesn't exist."""
if not os.path.exists(directory): # Checking if the directory doesn't exist
os.makedirs(directory) # Creating the directory if it doesn't exist
return directory # Returning the created or existing directory
#foldnumber = sys.argv[1]
foldnumber = "0" # Setting 'foldnumber' to "0"
folddirec = filedirec + os.sep + "Fold_" + foldnumber # Creating a directory path for the specific fold
trainfilename = "train_data" # Setting the name of the training data file
newtrainfilename = "train_data.QC" # Setting the name of the new training data file
testfilename = "test_data" # Setting the name of the test data file
newtestfilename = "test_data.QC" # Setting the name of the new test data file
# Number of PCA to be included as a covariate.
numberofpca = ["6"] # Setting the number of PCA components to be included
# Clumping parameters.
clump_p1 = [1] # List containing clump parameter 'p1'
clump_r2 = [0.1] # List containing clump parameter 'r2'
clump_kb = [200] # List containing clump parameter 'kb'
# Pruning parameters.
p_window_size = [200] # List containing pruning parameter 'window_size'
p_slide_size = [50] # List containing pruning parameter 'slide_size'
p_LD_threshold = [0.25] # List containing pruning parameter 'LD_threshold'
# Kindly note that the number of p-values to be considered varies, and the actual p-value depends on the dataset as well.
# We will specify the range list here.
minimumpvalue = 10 # Minimum p-value in exponent
numberofintervals = 20 # Number of intervals to be considered
allpvalues = np.logspace(-minimumpvalue, 0, numberofintervals, endpoint=True) # Generating an array of logarithmically spaced p-values
count = 1
with open(folddirec + os.sep + 'range_list', 'w') as file:
for value in allpvalues:
file.write(f'pv_{value} 0 {value}\n') # Writing range information to the 'range_list' file
count = count + 1
pvaluefile = folddirec + os.sep + 'range_list'
# Initializing an empty DataFrame with specified column names
prs_result = pd.DataFrame(columns=["clump_p1", "clump_r2", "clump_kb", "p_window_size", "p_slide_size", "p_LD_threshold",
"pvalue", "numberofpca","numberofvariants","Train_pure_prs", "Train_null_model", "Train_best_model",
"Test_pure_prs", "Test_null_model", "Test_best_model"])
Define Helper Functions#
Perform Clumping and Pruning
Calculate PCA Using Plink
Fit Binary Phenotype and Save Results
Fit Continuous Phenotype and Save Results
import os
import subprocess
import pandas as pd
import statsmodels.api as sm
from sklearn.metrics import explained_variance_score
def perform_clumping_and_pruning_on_individual_data(traindirec, newtrainfilename,numberofpca, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile):
command = [
"./plink",
"--bfile", traindirec+os.sep+newtrainfilename,
"--indep-pairwise", p1_val, p2_val, p3_val,
"--out", traindirec+os.sep+trainfilename
]
subprocess.run(command)
# First perform pruning and then clumping and the pruning.
command = [
"./plink",
"--bfile", traindirec+os.sep+newtrainfilename,
"--clump-p1", c1_val,
"--extract", traindirec+os.sep+trainfilename+".prune.in",
"--clump-r2", c2_val,
"--clump-kb", c3_val,
"--clump", filedirec+os.sep+filedirec+".txt",
"--clump-snp-field", "SNP",
"--clump-field", "P",
"--out", traindirec+os.sep+trainfilename
]
subprocess.run(command)
# Extract the valid SNPs from th clumped file.
# For windows download gwak for linux awk commmand is sufficient.
### For windows require GWAK.
### https://sourceforge.net/projects/gnuwin32/
##3 Get it and place it in the same direc.
#os.system("gawk "+"\""+"NR!=1{print $3}"+"\" "+ traindirec+os.sep+trainfilename+".clumped > "+traindirec+os.sep+trainfilename+".valid.snp")
#print("gawk "+"\""+"NR!=1{print $3}"+"\" "+ traindirec+os.sep+trainfilename+".clumped > "+traindirec+os.sep+trainfilename+".valid.snp")
#Linux:
command = f"awk 'NR!=1{{print $3}}' {traindirec}{os.sep}{trainfilename}.clumped > {traindirec}{os.sep}{trainfilename}.valid.snp"
os.system(command)
command = [
"./plink",
"--make-bed",
"--bfile", traindirec+os.sep+newtrainfilename,
"--indep-pairwise", p1_val, p2_val, p3_val,
"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--out", traindirec+os.sep+newtrainfilename+".clumped.pruned"
]
subprocess.run(command)
command = [
"./plink",
"--make-bed",
"--bfile", traindirec+os.sep+testfilename,
"--indep-pairwise", p1_val, p2_val, p3_val,
"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--out", traindirec+os.sep+testfilename+".clumped.pruned"
]
subprocess.run(command)
def calculate_pca_for_traindata_testdata_for_clumped_pruned_snps(traindirec, newtrainfilename,p):
# Calculate the PRS for the test data using the same set of SNPs and also calculate the PCA.
# Also extract the PCA at this point.
# PCA are calculated afer clumping and pruining.
command = [
"./plink",
"--bfile", folddirec+os.sep+testfilename+".clumped.pruned",
# Select the final variants after clumping and pruning.
"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--pca", p,
"--out", folddirec+os.sep+testfilename
]
subprocess.run(command)
command = [
"./plink",
"--bfile", traindirec+os.sep+newtrainfilename+".clumped.pruned",
# Select the final variants after clumping and pruning.
"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--pca", p,
"--out", traindirec+os.sep+trainfilename
]
subprocess.run(command)
# This function fit the binary model on the PRS.
def fit_binary_phenotype_on_PRS(traindirec, newtrainfilename, p,ref_dir,
va,vb,vc,vd,ve,vf,num_iter,beta_std,threshold,ignore_blk,fixtau,flip, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile):
threshold_values = allpvalues
# Merge the covariates, pca and phenotypes.
tempphenotype_train = pd.read_table(traindirec+os.sep+newtrainfilename+".clumped.pruned"+".fam", sep="\s+",header=None)
phenotype_train = pd.DataFrame()
phenotype_train["Phenotype"] = tempphenotype_train[5].values
pcs_train = pd.read_table(traindirec+os.sep+trainfilename+".eigenvec", sep="\s+",header=None, names=["FID", "IID"] + [f"PC{str(i)}" for i in range(1, int(p)+1)])
covariate_train = pd.read_table(traindirec+os.sep+trainfilename+".cov",sep="\s+")
covariate_train.fillna(0, inplace=True)
covariate_train = covariate_train[covariate_train["FID"].isin(pcs_train["FID"].values) & covariate_train["IID"].isin(pcs_train["IID"].values)]
covariate_train['FID'] = covariate_train['FID'].astype(str)
pcs_train['FID'] = pcs_train['FID'].astype(str)
covariate_train['IID'] = covariate_train['IID'].astype(str)
pcs_train['IID'] = pcs_train['IID'].astype(str)
covandpcs_train = pd.merge(covariate_train, pcs_train, on=["FID","IID"])
covandpcs_train.fillna(0, inplace=True)
## Scale the covariates!
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import explained_variance_score
scaler = MinMaxScaler()
normalized_values_train = scaler.fit_transform(covandpcs_train.iloc[:, 2:])
#covandpcs_train.iloc[:, 2:] = normalized_values_test
tempphenotype_test = pd.read_table(traindirec+os.sep+testfilename+".clumped.pruned"+".fam", sep="\s+",header=None)
phenotype_test= pd.DataFrame()
phenotype_test["Phenotype"] = tempphenotype_test[5].values
pcs_test = pd.read_table(traindirec+os.sep+testfilename+".eigenvec", sep="\s+",header=None, names=["FID", "IID"] + [f"PC{str(i)}" for i in range(1, int(p)+1)])
covariate_test = pd.read_table(traindirec+os.sep+testfilename+".cov",sep="\s+")
covariate_test.fillna(0, inplace=True)
covariate_test = covariate_test[covariate_test["FID"].isin(pcs_test["FID"].values) & covariate_test["IID"].isin(pcs_test["IID"].values)]
covariate_test['FID'] = covariate_test['FID'].astype(str)
pcs_test['FID'] = pcs_test['FID'].astype(str)
covariate_test['IID'] = covariate_test['IID'].astype(str)
pcs_test['IID'] = pcs_test['IID'].astype(str)
covandpcs_test = pd.merge(covariate_test, pcs_test, on=["FID","IID"])
covandpcs_test.fillna(0, inplace=True)
normalized_values_test = scaler.transform(covandpcs_test.iloc[:, 2:])
#covandpcs_test.iloc[:, 2:] = normalized_values_test
tempalphas = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
l1weights = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
tempalphas = [0.1]
l1weights = [0.1]
phenotype_train["Phenotype"] = phenotype_train["Phenotype"].replace({1: 0, 2: 1})
phenotype_test["Phenotype"] = phenotype_test["Phenotype"].replace({1: 0, 2: 1})
for tempalpha in tempalphas:
for l1weight in l1weights:
try:
null_model = sm.Logit(phenotype_train["Phenotype"], sm.add_constant(covandpcs_train.iloc[:, 2:])).fit_regularized(alpha=tempalpha, L1_wt=l1weight)
#null_model = sm.Logit(phenotype_train["Phenotype"], sm.add_constant(covandpcs_train.iloc[:, 2:])).fit()
except:
print("XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX")
continue
train_null_predicted = null_model.predict(sm.add_constant(covandpcs_train.iloc[:, 2:]))
from sklearn.metrics import roc_auc_score, confusion_matrix
from sklearn.metrics import r2_score
test_null_predicted = null_model.predict(sm.add_constant(covandpcs_test.iloc[:, 2:]))
global prs_result
for i in threshold_values:
try:
prs_train = pd.read_table(traindirec+os.sep+Name+os.sep+"train_data.pv_"+f"{i}.profile", sep="\s+", usecols=["FID", "IID", "SCORE"])
except:
continue
prs_train['FID'] = prs_train['FID'].astype(str)
prs_train['IID'] = prs_train['IID'].astype(str)
try:
prs_test = pd.read_table(traindirec+os.sep+Name+os.sep+"test_data.pv_"+f"{i}.profile", sep="\s+", usecols=["FID", "IID", "SCORE"])
except:
continue
prs_test['FID'] = prs_test['FID'].astype(str)
prs_test['IID'] = prs_test['IID'].astype(str)
pheno_prs_train = pd.merge(covandpcs_train, prs_train, on=["FID", "IID"])
pheno_prs_test = pd.merge(covandpcs_test, prs_test, on=["FID", "IID"])
try:
model = sm.Logit(phenotype_train["Phenotype"], sm.add_constant(pheno_prs_train.iloc[:, 2:])).fit_regularized(alpha=tempalpha, L1_wt=l1weight)
#model = sm.Logit(phenotype_train["Phenotype"], sm.add_constant(pheno_prs_train.iloc[:, 2:])).fit()
except:
continue
train_best_predicted = model.predict(sm.add_constant(pheno_prs_train.iloc[:, 2:]))
test_best_predicted = model.predict(sm.add_constant(pheno_prs_test.iloc[:, 2:]))
from sklearn.metrics import roc_auc_score, confusion_matrix
prs_result = prs_result._append({
"clump_p1": c1_val,
"clump_r2": c2_val,
"clump_kb": c3_val,
"p_window_size": p1_val,
"p_slide_size": p2_val,
"p_LD_threshold": p3_val,
"pvalue": i,
"numberofpca":p,
"tempalpha":str(tempalpha),
"l1weight":str(l1weight),
"PRSbils_ref_dir":ref_dir,
"PRSbils_va":va,
"PRSbils_vb":vb,
"PRSbils_thres":str(threshold),
"PRSbils_n_iter":str(num_iter),
"PRSbils_beta_std":str(beta_std),
"PRSbils_va":str(va),
"PRSbils_vb":str(vb),
"PRSbils_vc":str(vc),
"PRSbils_vd":str(vd),
"PRSbils_ve":str(ve),
"PRSbils_vf":str(vf),
"PRSbils_flip":str(flip),
"PRSbils_fixtau":str(fixtau),
"Train_pure_prs":roc_auc_score(phenotype_train["Phenotype"].values,prs_train['SCORE'].values),
"Train_null_model":roc_auc_score(phenotype_train["Phenotype"].values,train_null_predicted.values),
"Train_best_model":roc_auc_score(phenotype_train["Phenotype"].values,train_best_predicted.values),
"Test_pure_prs":roc_auc_score(phenotype_test["Phenotype"].values,prs_test['SCORE'].values),
"Test_null_model":roc_auc_score(phenotype_test["Phenotype"].values,test_null_predicted.values),
"Test_best_model":roc_auc_score(phenotype_test["Phenotype"].values,test_best_predicted.values),
}, ignore_index=True)
prs_result.to_csv(traindirec+os.sep+Name+os.sep+"Results.csv",index=False)
return
# This function fit the binary model on the PRS.
def fit_continous_phenotype_on_PRS(traindirec, newtrainfilename, p,ref_dir,
va,vb,vc,vd,ve,vf,num_iter,beta_std,threshold,ignore_blk,fixtau,flip, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile):
threshold_values = allpvalues
# Merge the covariates, pca and phenotypes.
tempphenotype_train = pd.read_table(traindirec+os.sep+newtrainfilename+".clumped.pruned"+".fam", sep="\s+",header=None)
phenotype_train = pd.DataFrame()
phenotype_train["Phenotype"] = tempphenotype_train[5].values
pcs_train = pd.read_table(traindirec+os.sep+trainfilename+".eigenvec", sep="\s+",header=None, names=["FID", "IID"] + [f"PC{str(i)}" for i in range(1, int(p)+1)])
covariate_train = pd.read_table(traindirec+os.sep+trainfilename+".cov",sep="\s+")
covariate_train.fillna(0, inplace=True)
covariate_train = covariate_train[covariate_train["FID"].isin(pcs_train["FID"].values) & covariate_train["IID"].isin(pcs_train["IID"].values)]
covariate_train['FID'] = covariate_train['FID'].astype(str)
pcs_train['FID'] = pcs_train['FID'].astype(str)
covariate_train['IID'] = covariate_train['IID'].astype(str)
pcs_train['IID'] = pcs_train['IID'].astype(str)
covandpcs_train = pd.merge(covariate_train, pcs_train, on=["FID","IID"])
covandpcs_train.fillna(0, inplace=True)
## Scale the covariates!
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import explained_variance_score
scaler = MinMaxScaler()
normalized_values_train = scaler.fit_transform(covandpcs_train.iloc[:, 2:])
#covandpcs_train.iloc[:, 2:] = normalized_values_test
tempphenotype_test = pd.read_table(traindirec+os.sep+testfilename+".clumped.pruned"+".fam", sep="\s+",header=None)
phenotype_test= pd.DataFrame()
phenotype_test["Phenotype"] = tempphenotype_test[5].values
pcs_test = pd.read_table(traindirec+os.sep+testfilename+".eigenvec", sep="\s+",header=None, names=["FID", "IID"] + [f"PC{str(i)}" for i in range(1, int(p)+1)])
covariate_test = pd.read_table(traindirec+os.sep+testfilename+".cov",sep="\s+")
covariate_test.fillna(0, inplace=True)
covariate_test = covariate_test[covariate_test["FID"].isin(pcs_test["FID"].values) & covariate_test["IID"].isin(pcs_test["IID"].values)]
covariate_test['FID'] = covariate_test['FID'].astype(str)
pcs_test['FID'] = pcs_test['FID'].astype(str)
covariate_test['IID'] = covariate_test['IID'].astype(str)
pcs_test['IID'] = pcs_test['IID'].astype(str)
covandpcs_test = pd.merge(covariate_test, pcs_test, on=["FID","IID"])
covandpcs_test.fillna(0, inplace=True)
normalized_values_test = scaler.transform(covandpcs_test.iloc[:, 2:])
#covandpcs_test.iloc[:, 2:] = normalized_values_test
tempalphas = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
l1weights = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
tempalphas = [0.1]
l1weights = [0.1]
#phenotype_train["Phenotype"] = phenotype_train["Phenotype"].replace({1: 0, 2: 1})
#phenotype_test["Phenotype"] = phenotype_test["Phenotype"].replace({1: 0, 2: 1})
for tempalpha in tempalphas:
for l1weight in l1weights:
try:
#null_model = sm.OLS(phenotype_train["Phenotype"], sm.add_constant(covandpcs_train.iloc[:, 2:])).fit_regularized(alpha=tempalpha, L1_wt=l1weight)
null_model = sm.OLS(phenotype_train["Phenotype"], sm.add_constant(covandpcs_train.iloc[:, 2:])).fit()
#null_model = sm.OLS(phenotype_train["Phenotype"], sm.add_constant(covandpcs_train.iloc[:, 2:])).fit()
except:
print("XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX")
continue
train_null_predicted = null_model.predict(sm.add_constant(covandpcs_train.iloc[:, 2:]))
from sklearn.metrics import roc_auc_score, confusion_matrix
from sklearn.metrics import r2_score
test_null_predicted = null_model.predict(sm.add_constant(covandpcs_test.iloc[:, 2:]))
global prs_result
for i in threshold_values:
try:
prs_train = pd.read_table(traindirec+os.sep+Name+os.sep+"train_data.pv_"+f"{i}.profile", sep="\s+", usecols=["FID", "IID", "SCORE"])
except:
continue
prs_train['FID'] = prs_train['FID'].astype(str)
prs_train['IID'] = prs_train['IID'].astype(str)
try:
prs_test = pd.read_table(traindirec+os.sep+Name+os.sep+"test_data.pv_"+f"{i}.profile", sep="\s+", usecols=["FID", "IID", "SCORE"])
except:
continue
prs_test['FID'] = prs_test['FID'].astype(str)
prs_test['IID'] = prs_test['IID'].astype(str)
pheno_prs_train = pd.merge(covandpcs_train, prs_train, on=["FID", "IID"])
pheno_prs_test = pd.merge(covandpcs_test, prs_test, on=["FID", "IID"])
try:
#model = sm.OLS(phenotype_train["Phenotype"], sm.add_constant(pheno_prs_train.iloc[:, 2:])).fit_regularized(alpha=tempalpha, L1_wt=l1weight)
model = sm.OLS(phenotype_train["Phenotype"], sm.add_constant(pheno_prs_train.iloc[:, 2:])).fit()
except:
continue
train_best_predicted = model.predict(sm.add_constant(pheno_prs_train.iloc[:, 2:]))
test_best_predicted = model.predict(sm.add_constant(pheno_prs_test.iloc[:, 2:]))
from sklearn.metrics import roc_auc_score, confusion_matrix
prs_result = prs_result._append({
"clump_p1": c1_val,
"clump_r2": c2_val,
"clump_kb": c3_val,
"p_window_size": p1_val,
"p_slide_size": p2_val,
"p_LD_threshold": p3_val,
"pvalue": i,
"numberofpca":p,
"tempalpha":str(tempalpha),
"l1weight":str(l1weight),
"PRSbils_ref_dir":ref_dir,
"PRSbils_thres":str(threshold),
"PRSbils_n_iter":str(num_iter),
"PRSbils_beta_std":str(beta_std),
"PRSbils_va":str(va),
"PRSbils_vb":str(vb),
"PRSbils_vc":str(vc),
"PRSbils_vd":str(vd),
"PRSbils_ve":str(ve),
"PRSbils_vf":str(vf),
"PRSbils_flip":str(flip),
"PRSbils_fixtau":str(fixtau),
"Train_pure_prs":explained_variance_score(phenotype_train["Phenotype"],prs_train['SCORE'].values),
"Train_null_model":explained_variance_score(phenotype_train["Phenotype"],train_null_predicted),
"Train_best_model":explained_variance_score(phenotype_train["Phenotype"],train_best_predicted),
"Test_pure_prs":explained_variance_score(phenotype_test["Phenotype"],prs_test['SCORE'].values),
"Test_null_model":explained_variance_score(phenotype_test["Phenotype"],test_null_predicted),
"Test_best_model":explained_variance_score(phenotype_test["Phenotype"],test_best_predicted),
}, ignore_index=True)
prs_result.to_csv(traindirec+os.sep+Name+os.sep+"Results.csv",index=False)
return
Execute PRSbils#
# Define a global variable to store results
prs_result = pd.DataFrame()
def transform_prsbils_data(traindirec, newtrainfilename, p,ref_dir,
va,vb,vc,vd,ve,vf,num_iter,beta_std,threshold,ignore_blk,fixtau,flip, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile):
### First perform clumping on the file and save the clumpled file.
# perform_clumping_and_pruning_on_individual_data(traindirec, newtrainfilename,p, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile)
#newtrainfilename = newtrainfilename+".clumped.pruned"
#testfilename = testfilename+".clumped.pruned"
#clupmedfile = traindirec+os.sep+newtrainfilename+".clump"
#prunedfile = traindirec+os.sep+newtrainfilename+".clumped.pruned"
# Also extract the PCA at this point for both test and training data.
# calculate_pca_for_traindata_testdata_for_clumped_pruned_snps(traindirec, newtrainfilename,p)
#Extract p-values from the GWAS file.
# Command for Linux.
os.system("awk "+"\'"+"{print $3,$8}"+"\'"+" ./"+filedirec+os.sep+filedirec+".txt > ./"+traindirec+os.sep+"SNP.pvalue")
# Command for windows.
### For windows get GWAK.
### https://sourceforge.net/projects/gnuwin32/
##3 Get it and place it in the same direc.
#os.system("gawk "+"\""+"{print $3,$8}"+"\""+" ./"+filedirec+os.sep+filedirec+".txt > ./"+traindirec+os.sep+"SNP.pvalue")
#print("gawk "+"\""+"{print $3,$8}"+"\""+" ./"+filedirec+os.sep+filedirec+".txt > ./"+traindirec+os.sep+"SNP.pvalue")
# Delete the files generated in the previous iteration.
import glob
file_list = glob.glob(traindirec+os.sep+"PRSbils_beta*.txt")
sorted_file_list = sorted(file_list, key=lambda x: int(''.join(filter(str.isdigit, x))))
def delete_files(file_list):
for file in file_list:
try:
os.remove(file)
print(f"File {file} deleted successfully.")
except FileNotFoundError:
print(f"File {file} not found.")
except Exception as e:
print(f"Error deleting file {file}: {e}")
delete_files(file_list)
files_to_remove = [
traindirec+os.sep+".PRSbilsNew",
]
# Loop through the files and remove them if they exist
for file_path in files_to_remove:
if os.path.exists(file_path):
os.remove(file_path)
print(f"Removed: {file_path}")
else:
print(f"File does not exist: {file_path}")
command = [
"python", # Use python3 instead of python
"PRSbils/PRSbils.py",
"--ref_dir=" + ref_dir,
"--bim_prefix=" + traindirec+os.sep+newtrainfilename+".clumped.pruned",
"--sst_file=" + filedirec + os.sep +filedirec+".PRSbils",
"--map_file="+"PRSbils/data/snpmap.txt",
"--n_gwas=" + str(int(n_gwas)),
"--out_dir=" + traindirec+os.sep+"PRSbils",
"--thres="+threshold,
"--n_iter="+str(num_iter),
#"--ignore_blk="+str(ignore_blk),
"--beta_std="+str(beta_std),
"--a="+str(va),
"--b="+str(vb),
"--c="+str(vc),
"--d="+str(vd),
"--e="+str(ve),
"--f="+str(vf),
"--flip="+str(flip),
"--fixtau="+str(fixtau)
]
print(" ".join(command))
subprocess.run(command)
import glob
file_list = glob.glob(traindirec+os.sep+"PRSbils_beta*.txt")
sorted_file_list = sorted(file_list, key=lambda x: int(''.join(filter(str.isdigit, x))))
merged_df = pd.DataFrame()
# Iterate through the files
for file in file_list:
try:
df = pd.read_csv(file, header=None,sep="\s+") # No header
merged_df = pd.concat([merged_df, df], ignore_index=True)
except:
pass
# Reset column names
merged_df = merged_df[[0,1,2,3,4,5,6]]
num_columns = len(merged_df.columns)
merged_df.columns = ["CHR","SNP","BP","A1","A2","OldBetas","NewBetas"]
if check_phenotype_is_binary_or_continous(filedirec)=="Binary":
merged_df["NewBetas"] = np.exp(merged_df["NewBetas"])
else:
pass
merged_df[["SNP","A1","NewBetas"]].to_csv(traindirec+os.sep+".PRSbilsNew",sep="\t",index=False)
command = [
"./plink",
"--bfile", traindirec+os.sep+newtrainfilename,
### SNP column = 3, Effect allele column 1 = 4, OR column=9
"--score", traindirec+os.sep +".PRSbilsNew", "1", "2", "3", "header",
"--q-score-range", traindirec+os.sep+"range_list",traindirec+os.sep+"SNP.pvalue",
#"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--out", traindirec+os.sep+Name+os.sep+trainfilename
]
#exit(0)
subprocess.run(command)
command = [
"./plink",
"--bfile", folddirec+os.sep+testfilename,
### SNP column = 3, Effect allele column 1 = 4, OR column=9
"--score", traindirec+os.sep +".PRSbilsNew", "1", "2", "3", "header",
"--q-score-range", traindirec+os.sep+"range_list",traindirec+os.sep+"SNP.pvalue",
"--extract", traindirec+os.sep+trainfilename+".valid.snp",
"--out", folddirec+os.sep+Name+os.sep+testfilename
]
subprocess.run(command)
if check_phenotype_is_binary_or_continous(filedirec)=="Binary":
print("Binary Phenotype!")
fit_binary_phenotype_on_PRS(traindirec, newtrainfilename, p,ref_dir,
va,vb,vc,vd,ve,vf,num_iter,beta_std,threshold,ignore_blk,fixtau,flip, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile)
else:
print("Continous Phenotype!")
fit_continous_phenotype_on_PRS(traindirec, newtrainfilename, p,ref_dir,
va,vb,vc,vd,ve,vf,num_iter,beta_std,threshold,ignore_blk,fixtau,flip, p1_val, p2_val, p3_val, c1_val, c2_val, c3_val,Name,pvaluefile)
"""
ref_dirs = ["ldblk_1kg_eur","ldblk_ukbb_eur"]
valuea = ['0.001']
valueb = ['0.001']
valuec = ['0.001']
valued = ['0.001']
valuee = ['1']
valuef = ['0.5']
number_of_iterations = ['1000']
beta_stds = [True,False]
thresholds = ['1e-04']
ignore_blks = [True,False]
fixtaus = [True,False]
flips = [True,False]
"""
ref_dirs = ["ldblk_1kg_eur","ldblk_ukbb_eur"]
ref_dirs = ["ldblk_1kg_eur" ]
valuea = ['0.001']
valueb = ['0.001']
valuec = ['0.001']
valued = ['0.001']
valuee = ['1']
valuef = ['0.5']
number_of_iterations = ['100']
beta_stds = [True ]
thresholds = ['1e-04']
ignore_blks = [True ]
fixtaus = [True ]
flips = [True ]
result_directory = "PRSbils"
# Nested loops to iterate over different parameter values
create_directory(folddirec+os.sep+result_directory)
for p1_val in p_window_size:
for p2_val in p_slide_size:
for p3_val in p_LD_threshold:
for c1_val in clump_p1:
for c2_val in clump_r2:
for c3_val in clump_kb:
for p in numberofpca:
for ref_dir in ref_dirs:
for va in valuea:
for vb in valueb:
for vc in valuec:
for vd in valued:
for ve in valuee:
for vf in valuef:
for num_iter in number_of_iterations:
for beta_std in beta_stds:
for threshold in thresholds:
for ignore_blk in ignore_blks:
for fixtau in fixtaus:
for flip in flips:
transform_prsbils_data(folddirec, newtrainfilename, p,ref_dir,
va,vb,vc,vd,ve,vf,num_iter,beta_std,threshold,ignore_blk,fixtau,flip, str(p1_val), str(p2_val), str(p3_val), str(c1_val), str(c2_val), str(c3_val), result_directory, pvaluefile)
Repeat the process for each fold.#
Change the foldnumber variable.
#foldnumber = sys.argv[1]
foldnumber = "0" # Setting 'foldnumber' to "0"
Or uncomment the following line:
# foldnumber = sys.argv[1]
python PRSbils.py 0
python PRSbils.py 1
python PRSbils.py 2
python PRSbils.py 3
python PRSbils.py 4
The following files should exist after the execution:
SampleData1/Fold_0/PRSbils/Results.csvSampleData1/Fold_1/PRSbils/Results.csvSampleData1/Fold_2/PRSbils/Results.csvSampleData1/Fold_3/PRSbils/Results.csvSampleData1/Fold_4/PRSbils/Results.csv
Check the results file for each fold.#
import os
result_directory = "PRSbils"
# List of file names to check for existence
f = [
"./"+filedirec+"/Fold_0"+os.sep+result_directory+"Results.csv",
"./"+filedirec+"/Fold_1"+os.sep+result_directory+"Results.csv",
"./"+filedirec+"/Fold_2"+os.sep+result_directory+"Results.csv",
"./"+filedirec+"/Fold_3"+os.sep+result_directory+"Results.csv",
"./"+filedirec+"/Fold_4"+os.sep+result_directory+"Results.csv",
]
# Loop through each file name in the list
for loop in range(0,5):
# Check if the file exists in the specified directory for the given fold
if os.path.exists(filedirec+os.sep+"Fold_"+str(loop)+os.sep+result_directory+os.sep+"Results.csv"):
temp = pd.read_csv(filedirec+os.sep+"Fold_"+str(loop)+os.sep+result_directory+os.sep+"Results.csv")
print("Fold_",loop, "Yes, the file exists.")
#print(temp.head())
print("Number of P-values processed: ",len(temp))
# Print a message indicating that the file exists
else:
# Print a message indicating that the file does not exist
print("Fold_",loop, "No, the file does not exist.")
Fold_ 0 Yes, the file exists.
Number of P-values processed: 20
Fold_ 1 Yes, the file exists.
Number of P-values processed: 20
Fold_ 2 Yes, the file exists.
Number of P-values processed: 20
Fold_ 3 Yes, the file exists.
Number of P-values processed: 20
Fold_ 4 Yes, the file exists.
Number of P-values processed: 20
Sum the results for each fold.#
print("We have to ensure when we sum the entries across all Folds, the same rows are merged!")
def sum_and_average_columns(data_frames):
"""Sum and average numerical columns across multiple DataFrames, and keep non-numerical columns unchanged."""
# Initialize DataFrame to store the summed results for numerical columns
summed_df = pd.DataFrame()
non_numerical_df = pd.DataFrame()
for df in data_frames:
# Identify numerical and non-numerical columns
numerical_cols = df.select_dtypes(include=[np.number]).columns
non_numerical_cols = df.select_dtypes(exclude=[np.number]).columns
# Sum numerical columns
if summed_df.empty:
summed_df = pd.DataFrame(0, index=range(len(df)), columns=numerical_cols)
summed_df[numerical_cols] = summed_df[numerical_cols].add(df[numerical_cols], fill_value=0)
# Keep non-numerical columns (take the first non-numerical entry for each column)
if non_numerical_df.empty:
non_numerical_df = df[non_numerical_cols]
else:
non_numerical_df[non_numerical_cols] = non_numerical_df[non_numerical_cols].combine_first(df[non_numerical_cols])
# Divide the summed values by the number of dataframes to get the average
averaged_df = summed_df / len(data_frames)
# Combine numerical and non-numerical DataFrames
result_df = pd.concat([averaged_df, non_numerical_df], axis=1)
return result_df
from functools import reduce
import os
import pandas as pd
from functools import reduce
def find_common_rows(allfoldsframe):
# Define the performance columns that need to be excluded
performance_columns = [
'Train_null_model', 'Train_pure_prs', 'Train_best_model',
'Test_pure_prs', 'Test_null_model', 'Test_best_model'
]
important_columns = [
'clump_p1',
'clump_r2',
'clump_kb',
'p_window_size',
'p_slide_size',
'p_LD_threshold',
'pvalue',
'referencepanel',
'numberofpca',
'tempalpha',
'l1weight',
"PRSbils_ref_dir",
"PRSbils_thres",
"PRSbils_n_iter",
"PRSbils_beta_std",
"PRSbils_va",
"PRSbils_vb",
"PRSbils_vc",
"PRSbils_vd",
"PRSbils_ve",
"PRSbils_vf",
"PRSbils_flip",
"PRSbils_fixtau",
]
# Function to remove performance columns from a DataFrame
def drop_performance_columns(df):
return df.drop(columns=performance_columns, errors='ignore')
def get_important_columns(df ):
existing_columns = [col for col in important_columns if col in df.columns]
if existing_columns:
return df[existing_columns].copy()
else:
return pd.DataFrame()
# Drop performance columns from all DataFrames in the list
allfoldsframe_dropped = [drop_performance_columns(df) for df in allfoldsframe]
# Get the important columns.
allfoldsframe_dropped = [get_important_columns(df) for df in allfoldsframe_dropped]
# Iteratively find common rows and track unique and common rows
common_rows = allfoldsframe_dropped[0]
for i in range(1, len(allfoldsframe_dropped)):
# Get the next DataFrame
next_df = allfoldsframe_dropped[i]
# Count unique rows in the current DataFrame and the next DataFrame
unique_in_common = common_rows.shape[0]
unique_in_next = next_df.shape[0]
# Find common rows between the current common_rows and the next DataFrame
common_rows = pd.merge(common_rows, next_df, how='inner')
# Count the common rows after merging
common_count = common_rows.shape[0]
# Print the unique and common row counts
print(f"Iteration {i}:")
print(f"Unique rows in current common DataFrame: {unique_in_common}")
print(f"Unique rows in next DataFrame: {unique_in_next}")
print(f"Common rows after merge: {common_count}\n")
# Now that we have the common rows, extract these from the original DataFrames
extracted_common_rows_frames = []
for original_df in allfoldsframe:
# Merge the common rows with the original DataFrame, keeping only the rows that match the common rows
extracted_common_rows = pd.merge(common_rows, original_df, how='inner', on=common_rows.columns.tolist())
# Add the DataFrame with the extracted common rows to the list
extracted_common_rows_frames.append(extracted_common_rows)
# Print the number of rows in the common DataFrames
for i, df in enumerate(extracted_common_rows_frames):
print(f"DataFrame {i + 1} with extracted common rows has {df.shape[0]} rows.")
# Return the list of DataFrames with extracted common rows
return extracted_common_rows_frames
# Example usage (assuming allfoldsframe is populated as shown earlier):
allfoldsframe = []
# Loop through each file name in the list
for loop in range(0, 5):
# Check if the file exists in the specified directory for the given fold
file_path = os.path.join(filedirec, "Fold_" + str(loop), result_directory, "Results.csv")
if os.path.exists(file_path):
allfoldsframe.append(pd.read_csv(file_path))
# Print a message indicating that the file exists
print("Fold_", loop, "Yes, the file exists.")
else:
# Print a message indicating that the file does not exist
print("Fold_", loop, "No, the file does not exist.")
# Find the common rows across all folds and return the list of extracted common rows
extracted_common_rows_list = find_common_rows(allfoldsframe)
# Sum the values column-wise
# For string values, do not sum it the values are going to be the same for each fold.
# Only sum the numeric values.
divided_result = sum_and_average_columns(extracted_common_rows_list)
print(divided_result)
We have to ensure when we sum the entries across all Folds, the same rows are merged!
Fold_ 0 Yes, the file exists.
Fold_ 1 Yes, the file exists.
Fold_ 2 Yes, the file exists.
Fold_ 3 Yes, the file exists.
Fold_ 4 Yes, the file exists.
Iteration 1:
Unique rows in current common DataFrame: 20
Unique rows in next DataFrame: 20
Common rows after merge: 20
Iteration 2:
Unique rows in current common DataFrame: 20
Unique rows in next DataFrame: 20
Common rows after merge: 20
Iteration 3:
Unique rows in current common DataFrame: 20
Unique rows in next DataFrame: 20
Common rows after merge: 20
Iteration 4:
Unique rows in current common DataFrame: 20
Unique rows in next DataFrame: 20
Common rows after merge: 20
DataFrame 1 with extracted common rows has 20 rows.
DataFrame 2 with extracted common rows has 20 rows.
DataFrame 3 with extracted common rows has 20 rows.
DataFrame 4 with extracted common rows has 20 rows.
DataFrame 5 with extracted common rows has 20 rows.
clump_p1 clump_r2 clump_kb p_window_size p_slide_size p_LD_threshold \
0 1.0 0.1 200.0 200.0 50.0 0.25
1 1.0 0.1 200.0 200.0 50.0 0.25
2 1.0 0.1 200.0 200.0 50.0 0.25
3 1.0 0.1 200.0 200.0 50.0 0.25
4 1.0 0.1 200.0 200.0 50.0 0.25
5 1.0 0.1 200.0 200.0 50.0 0.25
6 1.0 0.1 200.0 200.0 50.0 0.25
7 1.0 0.1 200.0 200.0 50.0 0.25
8 1.0 0.1 200.0 200.0 50.0 0.25
9 1.0 0.1 200.0 200.0 50.0 0.25
10 1.0 0.1 200.0 200.0 50.0 0.25
11 1.0 0.1 200.0 200.0 50.0 0.25
12 1.0 0.1 200.0 200.0 50.0 0.25
13 1.0 0.1 200.0 200.0 50.0 0.25
14 1.0 0.1 200.0 200.0 50.0 0.25
15 1.0 0.1 200.0 200.0 50.0 0.25
16 1.0 0.1 200.0 200.0 50.0 0.25
17 1.0 0.1 200.0 200.0 50.0 0.25
18 1.0 0.1 200.0 200.0 50.0 0.25
19 1.0 0.1 200.0 200.0 50.0 0.25
pvalue numberofpca tempalpha l1weight ... Train_pure_prs \
0 1.000000e-10 6.0 0.1 0.1 ... 0.0
1 3.359818e-10 6.0 0.1 0.1 ... 0.0
2 1.128838e-09 6.0 0.1 0.1 ... 0.0
3 3.792690e-09 6.0 0.1 0.1 ... 0.0
4 1.274275e-08 6.0 0.1 0.1 ... 0.0
5 4.281332e-08 6.0 0.1 0.1 ... 0.0
6 1.438450e-07 6.0 0.1 0.1 ... 0.0
7 4.832930e-07 6.0 0.1 0.1 ... 0.0
8 1.623777e-06 6.0 0.1 0.1 ... 0.0
9 5.455595e-06 6.0 0.1 0.1 ... 0.0
10 1.832981e-05 6.0 0.1 0.1 ... 0.0
11 6.158482e-05 6.0 0.1 0.1 ... 0.0
12 2.069138e-04 6.0 0.1 0.1 ... 0.0
13 6.951928e-04 6.0 0.1 0.1 ... 0.0
14 2.335721e-03 6.0 0.1 0.1 ... 0.0
15 7.847600e-03 6.0 0.1 0.1 ... 0.0
16 2.636651e-02 6.0 0.1 0.1 ... 0.0
17 8.858668e-02 6.0 0.1 0.1 ... 0.0
18 2.976351e-01 6.0 0.1 0.1 ... 0.0
19 1.000000e+00 6.0 0.1 0.1 ... 0.0
Train_null_model Train_best_model Test_pure_prs Test_null_model \
0 0.23001 0.23001 0.0 0.118692
1 0.23001 0.23001 0.0 0.118692
2 0.23001 0.23001 0.0 0.118692
3 0.23001 0.23001 0.0 0.118692
4 0.23001 0.23001 0.0 0.118692
5 0.23001 0.23001 0.0 0.118692
6 0.23001 0.23001 0.0 0.118692
7 0.23001 0.23001 0.0 0.118692
8 0.23001 0.23001 0.0 0.118692
9 0.23001 0.23001 0.0 0.118692
10 0.23001 0.23001 0.0 0.118692
11 0.23001 0.23001 0.0 0.118692
12 0.23001 0.23001 0.0 0.118692
13 0.23001 0.23001 0.0 0.118692
14 0.23001 0.23001 0.0 0.118692
15 0.23001 0.23001 0.0 0.118692
16 0.23001 0.23001 0.0 0.118692
17 0.23001 0.23001 0.0 0.118692
18 0.23001 0.23001 0.0 0.118692
19 0.23001 0.23001 0.0 0.118692
Test_best_model PRSbils_ref_dir PRSbils_beta_std PRSbils_flip \
0 0.118692 ldblk_1kg_eur True True
1 0.118692 ldblk_1kg_eur True True
2 0.118692 ldblk_1kg_eur True True
3 0.118692 ldblk_1kg_eur True True
4 0.118692 ldblk_1kg_eur True True
5 0.118692 ldblk_1kg_eur True True
6 0.118692 ldblk_1kg_eur True True
7 0.118692 ldblk_1kg_eur True True
8 0.118692 ldblk_1kg_eur True True
9 0.118692 ldblk_1kg_eur True True
10 0.118692 ldblk_1kg_eur True True
11 0.118692 ldblk_1kg_eur True True
12 0.118692 ldblk_1kg_eur True True
13 0.118692 ldblk_1kg_eur True True
14 0.118692 ldblk_1kg_eur True True
15 0.118692 ldblk_1kg_eur True True
16 0.118692 ldblk_1kg_eur True True
17 0.118692 ldblk_1kg_eur True True
18 0.118692 ldblk_1kg_eur True True
19 0.118692 ldblk_1kg_eur True True
PRSbils_fixtau
0 True
1 True
2 True
3 True
4 True
5 True
6 True
7 True
8 True
9 True
10 True
11 True
12 True
13 True
14 True
15 True
16 True
17 True
18 True
19 True
[20 rows x 28 columns]
/tmp/ipykernel_2365626/1863169958.py:24: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
non_numerical_df[non_numerical_cols] = non_numerical_df[non_numerical_cols].combine_first(df[non_numerical_cols])
/tmp/ipykernel_2365626/1863169958.py:24: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
non_numerical_df[non_numerical_cols] = non_numerical_df[non_numerical_cols].combine_first(df[non_numerical_cols])
/tmp/ipykernel_2365626/1863169958.py:24: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
non_numerical_df[non_numerical_cols] = non_numerical_df[non_numerical_cols].combine_first(df[non_numerical_cols])
/tmp/ipykernel_2365626/1863169958.py:24: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
non_numerical_df[non_numerical_cols] = non_numerical_df[non_numerical_cols].combine_first(df[non_numerical_cols])
Results#
1. Reporting Based on Best Training Performance:#
One can report the results based on the best performance of the training data. For example, if for a specific combination of hyperparameters, the training performance is high, report the corresponding test performance.
Example code:
df = divided_result.sort_values(by='Train_best_model', ascending=False) print(df.iloc[0].to_markdown())
Binary Phenotypes Result Analysis#
You can find the performance quality for binary phenotype using the following template:
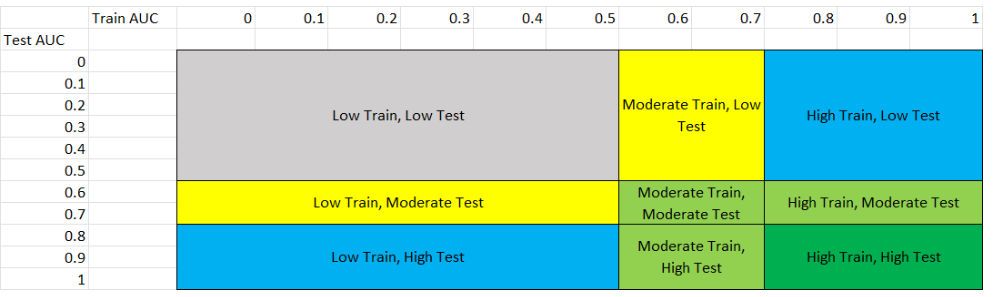
This figure shows the 8 different scenarios that can exist in the results, and the following table explains each scenario.
We classified performance based on the following table:
Performance Level |
Range |
|---|---|
Low Performance |
0 to 0.5 |
Moderate Performance |
0.6 to 0.7 |
High Performance |
0.8 to 1 |
You can match the performance based on the following scenarios:
Scenario |
What’s Happening |
Implication |
|---|---|---|
High Test, High Train |
The model performs well on both training and test datasets, effectively learning the underlying patterns. |
The model is well-tuned, generalizes well, and makes accurate predictions on both datasets. |
High Test, Moderate Train |
The model generalizes well but may not be fully optimized on training data, missing some underlying patterns. |
The model is fairly robust but may benefit from further tuning or more training to improve its learning. |
High Test, Low Train |
An unusual scenario, potentially indicating data leakage or overestimation of test performance. |
The model’s performance is likely unreliable; investigate potential data issues or random noise. |
Moderate Test, High Train |
The model fits the training data well but doesn’t generalize as effectively, capturing only some test patterns. |
The model is slightly overfitting; adjustments may be needed to improve generalization on unseen data. |
Moderate Test, Moderate Train |
The model shows balanced but moderate performance on both datasets, capturing some patterns but missing others. |
The model is moderately fitting; further improvements could be made in both training and generalization. |
Moderate Test, Low Train |
The model underperforms on training data and doesn’t generalize well, leading to moderate test performance. |
The model may need more complexity, additional features, or better training to improve on both datasets. |
Low Test, High Train |
The model overfits the training data, performing poorly on the test set. |
The model doesn’t generalize well; simplifying the model or using regularization may help reduce overfitting. |
Low Test, Low Train |
The model performs poorly on both training and test datasets, failing to learn the data patterns effectively. |
The model is underfitting; it may need more complexity, additional features, or more data to improve performance. |
Recommendations for Publishing Results#
When publishing results, scenarios with moderate train and moderate test performance can be used for complex phenotypes or diseases. However, results showing high train and moderate test, high train and high test, and moderate train and high test are recommended.
For most phenotypes, results typically fall in the moderate train and moderate test performance category.
Continuous Phenotypes Result Analysis#
You can find the performance quality for continuous phenotypes using the following template:
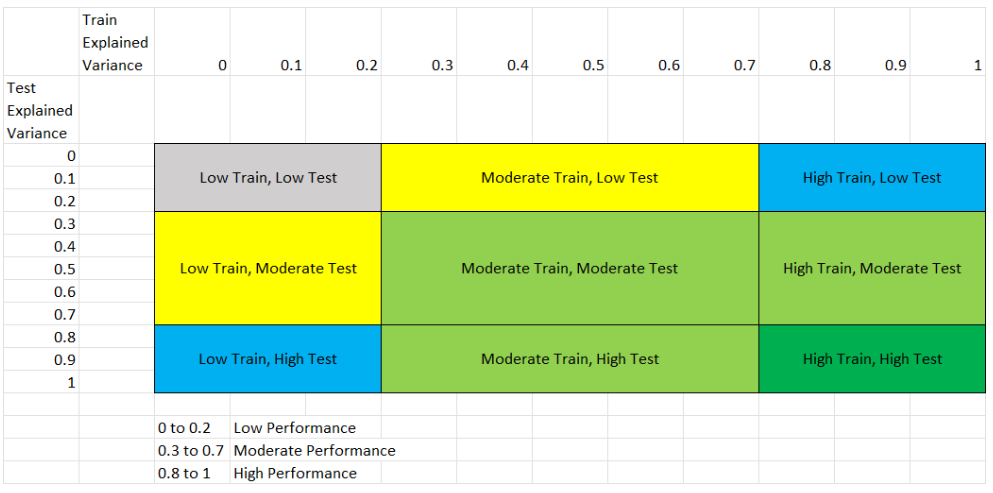
This figure shows the 8 different scenarios that can exist in the results, and the following table explains each scenario.
We classified performance based on the following table:
Performance Level |
Range |
|---|---|
Low Performance |
0 to 0.2 |
Moderate Performance |
0.3 to 0.7 |
High Performance |
0.8 to 1 |
You can match the performance based on the following scenarios:
Scenario |
What’s Happening |
Implication |
|---|---|---|
High Test, High Train |
The model performs well on both training and test datasets, effectively learning the underlying patterns. |
The model is well-tuned, generalizes well, and makes accurate predictions on both datasets. |
High Test, Moderate Train |
The model generalizes well but may not be fully optimized on training data, missing some underlying patterns. |
The model is fairly robust but may benefit from further tuning or more training to improve its learning. |
High Test, Low Train |
An unusual scenario, potentially indicating data leakage or overestimation of test performance. |
The model’s performance is likely unreliable; investigate potential data issues or random noise. |
Moderate Test, High Train |
The model fits the training data well but doesn’t generalize as effectively, capturing only some test patterns. |
The model is slightly overfitting; adjustments may be needed to improve generalization on unseen data. |
Moderate Test, Moderate Train |
The model shows balanced but moderate performance on both datasets, capturing some patterns but missing others. |
The model is moderately fitting; further improvements could be made in both training and generalization. |
Moderate Test, Low Train |
The model underperforms on training data and doesn’t generalize well, leading to moderate test performance. |
The model may need more complexity, additional features, or better training to improve on both datasets. |
Low Test, High Train |
The model overfits the training data, performing poorly on the test set. |
The model doesn’t generalize well; simplifying the model or using regularization may help reduce overfitting. |
Low Test, Low Train |
The model performs poorly on both training and test datasets, failing to learn the data patterns effectively. |
The model is underfitting; it may need more complexity, additional features, or more data to improve performance. |
Recommendations for Publishing Results#
When publishing results, scenarios with moderate train and moderate test performance can be used for complex phenotypes or diseases. However, results showing high train and moderate test, high train and high test, and moderate train and high test are recommended.
For most continuous phenotypes, results typically fall in the moderate train and moderate test performance category.
2. Reporting Generalized Performance:#
One can also report the generalized performance by calculating the difference between the training and test performance, and the sum of the test and training performance. Report the result or hyperparameter combination for which the sum is high and the difference is minimal.
Example code:
df = divided_result.copy() df['Difference'] = abs(df['Train_best_model'] - df['Test_best_model']) df['Sum'] = df['Train_best_model'] + df['Test_best_model'] sorted_df = df.sort_values(by=['Sum', 'Difference'], ascending=[False, True]) print(sorted_df.iloc[0].to_markdown())
3. Reporting Hyperparameters Affecting Test and Train Performance:#
Find the hyperparameters that have more than one unique value and calculate their correlation with the following columns to understand how they are affecting the performance of train and test sets:
Train_null_modelTrain_pure_prsTrain_best_modelTest_pure_prsTest_null_modelTest_best_model
4. Other Analysis#
Once you have the results, you can find how hyperparameters affect the model performance.
Analysis, like overfitting and underfitting, can be performed as well.
The way you are going to report the results can vary.
Results can be visualized, and other patterns in the data can be explored.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib notebook
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
df = divided_result.sort_values(by='Train_best_model', ascending=False)
print("1. Reporting Based on Best Training Performance:\n")
print(df.iloc[0].to_markdown())
df = divided_result.copy()
# Plot Train and Test best models against p-values
plt.figure(figsize=(10, 6))
plt.plot(df['pvalue'], df['Train_best_model'], label='Train_best_model', marker='o', color='royalblue')
plt.plot(df['pvalue'], df['Test_best_model'], label='Test_best_model', marker='o', color='darkorange')
# Highlight the p-value where both train and test are high
best_index = df[['Train_best_model']].sum(axis=1).idxmax()
best_pvalue = df.loc[best_index, 'pvalue']
best_train = df.loc[best_index, 'Train_best_model']
best_test = df.loc[best_index, 'Test_best_model']
# Use dark colors for the circles
plt.scatter(best_pvalue, best_train, color='darkred', s=100, label=f'Best Performance (Train)', edgecolor='black', zorder=5)
plt.scatter(best_pvalue, best_test, color='darkblue', s=100, label=f'Best Performance (Test)', edgecolor='black', zorder=5)
# Annotate the best performance with p-value, train, and test values
plt.text(best_pvalue, best_train, f'p={best_pvalue:.4g}\nTrain={best_train:.4g}', ha='right', va='bottom', fontsize=9, color='darkred')
plt.text(best_pvalue, best_test, f'p={best_pvalue:.4g}\nTest={best_test:.4g}', ha='right', va='top', fontsize=9, color='darkblue')
# Calculate Difference and Sum
df['Difference'] = abs(df['Train_best_model'] - df['Test_best_model'])
df['Sum'] = df['Train_best_model'] + df['Test_best_model']
# Sort the DataFrame
sorted_df = df.sort_values(by=['Sum', 'Difference'], ascending=[False, True])
#sorted_df = df.sort_values(by=[ 'Difference','Sum'], ascending=[ True,False])
# Highlight the general performance
general_index = sorted_df.index[0]
general_pvalue = sorted_df.loc[general_index, 'pvalue']
general_train = sorted_df.loc[general_index, 'Train_best_model']
general_test = sorted_df.loc[general_index, 'Test_best_model']
plt.scatter(general_pvalue, general_train, color='darkgreen', s=150, label='General Performance (Train)', edgecolor='black', zorder=6)
plt.scatter(general_pvalue, general_test, color='darkorange', s=150, label='General Performance (Test)', edgecolor='black', zorder=6)
# Annotate the general performance with p-value, train, and test values
plt.text(general_pvalue, general_train, f'p={general_pvalue:.4g}\nTrain={general_train:.4g}', ha='left', va='bottom', fontsize=9, color='darkgreen')
plt.text(general_pvalue, general_test, f'p={general_pvalue:.4g}\nTest={general_test:.4g}', ha='left', va='top', fontsize=9, color='darkorange')
# Add labels and legend
plt.xlabel('p-value')
plt.ylabel('Model Performance')
plt.title('Train vs Test Best Models')
plt.legend()
plt.show()
print("2. Reporting Generalized Performance:\n")
df = divided_result.copy()
df['Difference'] = abs(df['Train_best_model'] - df['Test_best_model'])
df['Sum'] = df['Train_best_model'] + df['Test_best_model']
sorted_df = df.sort_values(by=['Sum', 'Difference'], ascending=[False, True])
print(sorted_df.iloc[0].to_markdown())
print("3. Reporting the correlation of hyperparameters and the performance of 'Train_null_model', 'Train_pure_prs', 'Train_best_model', 'Test_pure_prs', 'Test_null_model', and 'Test_best_model':\n")
print("3. For string hyperparameters, we used one-hot encoding to find the correlation between string hyperparameters and 'Train_null_model', 'Train_pure_prs', 'Train_best_model', 'Test_pure_prs', 'Test_null_model', and 'Test_best_model'.")
print("3. We performed this analysis for those hyperparameters that have more than one unique value.")
correlation_columns = [
'Train_null_model', 'Train_pure_prs', 'Train_best_model',
'Test_pure_prs', 'Test_null_model', 'Test_best_model'
]
hyperparams = [col for col in divided_result.columns if len(divided_result[col].unique()) > 1]
hyperparams = list(set(hyperparams+correlation_columns))
# Separate numeric and string columns
numeric_hyperparams = [col for col in hyperparams if pd.api.types.is_numeric_dtype(divided_result[col])]
string_hyperparams = [col for col in hyperparams if pd.api.types.is_string_dtype(divided_result[col])]
# Encode string columns using one-hot encoding
divided_result_encoded = pd.get_dummies(divided_result, columns=string_hyperparams)
# Combine numeric hyperparams with the new one-hot encoded columns
encoded_columns = [col for col in divided_result_encoded.columns if col.startswith(tuple(string_hyperparams))]
hyperparams = numeric_hyperparams + encoded_columns
# Calculate correlations
correlations = divided_result_encoded[hyperparams].corr()
# Display correlation of hyperparameters with train/test performance columns
hyperparam_correlations = correlations.loc[hyperparams, correlation_columns]
hyperparam_correlations = hyperparam_correlations.fillna(0)
# Plotting the correlation heatmap
plt.figure(figsize=(12, 8))
ax = sns.heatmap(hyperparam_correlations, annot=True, cmap='viridis', fmt='.2f', cbar=True)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90, ha='right')
# Rotate y-axis labels to horizontal
#ax.set_yticklabels(ax.get_yticklabels(), rotation=0, va='center')
plt.title('Correlation of Hyperparameters with Train/Test Performance')
plt.show()
sns.set_theme(style="whitegrid") # Choose your preferred style
pairplot = sns.pairplot(divided_result_encoded[hyperparams],hue = 'Test_best_model', palette='viridis')
# Adjust the figure size
pairplot.fig.set_size_inches(15, 15) # You can adjust the size as needed
for ax in pairplot.axes.flatten():
ax.set_xlabel(ax.get_xlabel(), rotation=90, ha='right') # X-axis labels vertical
#ax.set_ylabel(ax.get_ylabel(), rotation=0, va='bottom') # Y-axis labels horizontal
# Show the plot
plt.show()
1. Reporting Based on Best Training Performance:
| | 0 |
|:-----------------|:--------------------|
| clump_p1 | 1.0 |
| clump_r2 | 0.1 |
| clump_kb | 200.0 |
| p_window_size | 200.0 |
| p_slide_size | 50.0 |
| p_LD_threshold | 0.25 |
| pvalue | 1e-10 |
| numberofpca | 6.0 |
| tempalpha | 0.1 |
| l1weight | 0.1 |
| PRSbils_thres | 0.1 |
| PRSbils_n_iter | 100.0 |
| PRSbils_va | 0.001 |
| PRSbils_vb | 0.001 |
| PRSbils_vc | 0.001 |
| PRSbils_vd | 0.001 |
| PRSbils_ve | 1.0 |
| PRSbils_vf | 0.5 |
| Train_pure_prs | 0.0 |
| Train_null_model | 0.23001030414198947 |
| Train_best_model | 0.23001030414198978 |
| Test_pure_prs | 0.0 |
| Test_null_model | 0.11869244971793831 |
| Test_best_model | 0.11869244971794106 |
| PRSbils_ref_dir | ldblk_1kg_eur |
| PRSbils_beta_std | True |
| PRSbils_flip | True |
| PRSbils_fixtau | True |

2. Reporting Generalized Performance:
| | 0 |
|:-----------------|:--------------------|
| clump_p1 | 1.0 |
| clump_r2 | 0.1 |
| clump_kb | 200.0 |
| p_window_size | 200.0 |
| p_slide_size | 50.0 |
| p_LD_threshold | 0.25 |
| pvalue | 1e-10 |
| numberofpca | 6.0 |
| tempalpha | 0.1 |
| l1weight | 0.1 |
| PRSbils_thres | 0.1 |
| PRSbils_n_iter | 100.0 |
| PRSbils_va | 0.001 |
| PRSbils_vb | 0.001 |
| PRSbils_vc | 0.001 |
| PRSbils_vd | 0.001 |
| PRSbils_ve | 1.0 |
| PRSbils_vf | 0.5 |
| Train_pure_prs | 0.0 |
| Train_null_model | 0.23001030414198947 |
| Train_best_model | 0.23001030414198978 |
| Test_pure_prs | 0.0 |
| Test_null_model | 0.11869244971793831 |
| Test_best_model | 0.11869244971794106 |
| PRSbils_ref_dir | ldblk_1kg_eur |
| PRSbils_beta_std | True |
| PRSbils_flip | True |
| PRSbils_fixtau | True |
| Difference | 0.11131785442404872 |
| Sum | 0.3487027538599308 |
3. Reporting the correlation of hyperparameters and the performance of 'Train_null_model', 'Train_pure_prs', 'Train_best_model', 'Test_pure_prs', 'Test_null_model', and 'Test_best_model':
3. For string hyperparameters, we used one-hot encoding to find the correlation between string hyperparameters and 'Train_null_model', 'Train_pure_prs', 'Train_best_model', 'Test_pure_prs', 'Test_null_model', and 'Test_best_model'.
3. We performed this analysis for those hyperparameters that have more than one unique value.

